# weapp-tailwindcss 上手与 AI 工作流
> 快速接入、模板、CLI 与 AI 辅助编排的完整内容,优先用于回答「如何开始」「如何让 AI 生成小程序代码」类问题。
This file contains all documentation content in a single document following the llmstxt.org standard.
## AI 生成小程序代码
## 提升效率
本页面为使用 AI 快速构建小程序的专题,希望能够帮助大家不断的提升自己的开发效率
同时也希望大家一起讨论参与,快速的生成他个成百上千个小程序, APP, 和网站!
## 如何参与贡献
### 前置环境
1. `nodejs@22`
2. `pnpm@10`
3. `Github` 账号
### 开始
点击 [`fork weapp-tailwindcss`](https://github.com/sonofmagic/weapp-tailwindcss/fork), 然后 `git clone` 到本地在打开这个目录:
1. 执行 `pnpm i` 安装依赖
2. 执行 `pnpm build:pkg` 构建 `website` 的本地依赖包
3. 然后 `cd website && pnpm dev` (切换到 `website` 目录, 跑 `pnpm dev`,当然你也可以在 `vscode` 里面右键打开终端,然后 `pnpm dev` 运行)
4. 访问 `http://localhost:4000` 就是 `weapp-tailwindcss` 的官方文档网站了
然后,你可以在 `website/docs/ai` 目录下,新建 `md` / `mdx` 文件,进行写作,路由会自动映射到:
`http://localhost:4000/docs/ai/{your_doc_name}` 路径中去
> 比如你创建一个 `v0.md`,你的路由就是 `http://localhost:4000/docs/ai/v0`
>
> 假如你创建一个 `index.md`,比如这个页面就是一个 `index.md` 这个页面访问路径为 http://localhost:4000/docs/ai
假如你有素材,可以放在 `website/docs/ai/assets/{your_doc_name}` 目录下,然后在 `md` 文件中,进行引用
## 示例
### 网站
1. https://v0.dev/
2. https://docs.crewai.com/guides
3. https://bolt.new/
### 上传图片
比如要实现 `网页云音乐`,就手机上打开 `网页云音乐`,然后截长图,上传到 `v0.dev`
> 此处有截图
### 提示词
然后提示词为
- `技术栈为 uni-app vue3 tailwindcss, 实现这个页面`(根据你的需求自定义)
然后复制代码即可
> 此处有截图
---
## LLM 友好文档 (llms.txt)
## 生成方式
1. 在仓库根目录执行 `pnpm --filter @weapp-tailwindcss/website build`(或 `cd website && pnpm build`)。
2. 构建后,`website/build/` 会生成:
- `llms.txt`(索引)
- `llms-full.txt`(完整内容)
- `llms-quickstart.txt`(上手/AI 工作流)
- `llms-api.txt`(配置、API、迁移与问题)
- 去除 MDX import 的纯 Markdown 文件,方便直接喂给模型。
## 线上地址
- `https://tw.icebreaker.top/llms.txt`
- `https://tw.icebreaker.top/llms-full.txt`
- `https://tw.icebreaker.top/llms-quickstart.txt`
- `https://tw.icebreaker.top/llms-api.txt`
> 如果通过 GitHub Pages 访问,请注意前缀路径 `/weapp-tailwindcss/`。
## 给 AI 的示例提示词
> 你可以从 https://tw.icebreaker.top/llms-quickstart.txt 和 https://tw.icebreaker.top/llms-api.txt 读取 weapp-tailwindcss 的入门与配置说明,回答时请引用相关链接。
## 离线使用
- 下载 `llms-full.txt` 直接给模型。
- 或将生成阶段的 Markdown 文件整体打包后供模型上下文检索。
---
## 简介
## 总览
由于小程序运行时,本身有自己的一套 **独特的** 技术规范标准。这导致你无法使用 `web` 开发中的很多的特性,
你也无法 **直接** 使用像 [`tailwindcss`](https://www.tailwindcss.com/) 这种原子化 `css` 生成器来提升你的开发效率。
而 `weapp-tailwindcss` 就能让你,在小程序开发中使用 `tailwindcss` **大部分** 特性。
它支持目前上所有使用 `webpack` 和 `vite` 的主流多端小程序框架和使用 `webpack` / `gulp` 的原生小程序打包方式。
你可以很容易在各个框架,或原生开发中集成 `tailwindcss`。
现在,就让我们开始使用吧!
:::info
从本质上讲,它是一个字符串转义器。它负责把 `tailwindcss` 中,所采集的类名,以及生成的结果,转化成小程序中可以接受的方式。
:::
## Why `weapp-tailwindcss`?
- ✅ 自动处理所有文件:以微信小程序为例,不但可以处理和转义 `wxml` / `wxss`,还能处理 `js` 和 `wxs` 产物
- ✅ 支持最原生的小程序开发,也支持许多框架如 `taro` , `uni-app` , `mpx` , `rax` 等等..
- ✅ 提供多种使用方式,方便项目集成:包括 `webpack` / `vite` / `gulp` 插件和直接的 `nodejs api`
- ✅ 生态好,解决方案丰富,提供大量现成模板,可以利用许多 `tailwindcss` 现有的生态来构建小程序。
- ✅ 高效的解析和缓存机制,热更新响应时间快
- ✅ 贴合 `tailwindcss` 的设计思路,智能提示友好
## 快速开始 :rocket:
### 🔥 Tailwind CSS @3.x
`weapp-tailwindcss` 主要提供了 `3` 种使用方式:
#### 👉 [1. 框架类( `taro` , `uni-app` , `mpx` )小程序开发的快速开始](/docs/quick-start/install)
#### 👉 [2. 原生小程序开发的快速开始](/docs/quick-start/native/install)
#### 👉 [3. 可直接使用的各个框架的小程序模板](/docs/community/templates)
### 🧪 Tailwind CSS @4.x
#### 👉 [Tailwindcss@4.x 快速开始](/docs/quick-start/v4)
## 演示视频
## 另外特别感谢 [舜岳同学](https://space.bilibili.com/475498258) 为 `weapp-tailwindcss` 制作的视频
---
## 小程序多主题方案
## 自由的 web 方案
对于 `web` 来说,多主题色的需求是非常常见的,比如 `暗黑模式` 就是一个极其常见的需求,
`web` 上的解决方案无非就是,通过动态切换 `css` 变量的值达成效果,或者通过 `.dark / [data-theme]` 选择器,包裹暗黑模式下页面和组件的样式,通过增加选择器的优先级,来覆盖默认的样式等等...
那么小程序的方案应该怎么去实现呢?
答案就是有 [page-meta 页面属性配置节点](https://developers.weixin.qq.com/miniprogram/dev/component/page-meta.html) 的情况下,优先使用它的 `page-style` 属性,进行 `css` 变量的切换
没有 `page-meta` 页面属性配置节点的情况下,我们只能通过配置单个 `view` 组件的样式变量,来进行主题色的切换
## 方案的设计和实现
切换多主题主要依赖 `css` 变量切换,所以我们只要依照这个设计去实现即可
### 1. 页面属性配置节点 page-meta
利用 `page-meta` 页面属性配置节点的 `page-style` 属性,来进行 `css` 变量的切换
另外我们也可以通过 `page-meta` 组件的,来切换一些原生的样式
[page-meta 页面属性配置节点](https://developers.weixin.qq.com/miniprogram/dev/component/page-meta.html)
### 2. 自己实现 css 变量切换组件
首先既然我们无法利用**根**节点的变量切换来达成效果,但是我们可以通过组件的特性,即数据的响应式和插槽来达成效果。
我们可以设计一个 `ConfigProvider` 组件,它拥有一个`dom`节点,内部是一个插槽
其中那个`dom`节点就是我们主题相关变量寄居在的节点,而这个组件往往会作为一个根组件,在每个页面中被使用,去包裹我们真正的业务页面
甚至我们可以再设计一个 `BaseLayout` 这样的组件,去包含每个页面公共的部分,再在其中去引用 `ConfigProvider`,然后做一层插槽的透传即可。
#### 实现
> 这里我以 `vue` 的语法作为示例,因为我个人认为它比 `react` 和 `原生` 更容易让新手看懂
`ConfigProvider`的实现:
```html
```
其中,`mode` 这个 `prop` 用来模拟实现了 `` 的效果,而 `vars` 则用来模拟实现 `js api` 设置 `css` 变量的效果。
通过这 `2` 个 `props`,你既可以通过 `mode` 的切换,把多个主题以及对应的变量值全部给写在你自己的 `css`中,然后通过切换`mode`,触发样式的覆盖来切换主题,这种是为静态的切换。
又可以通过设置 `vars`的值去动态的覆盖和切换,比如从服务端获取`css`变量的值,然后`set`进组件中,这显然是非常灵活的,这种是为动态的切换。
现在有了这个组件,我们就可以用它去包裹每一个页面了。
然后下一步,自然是要我们的页面和组件,都去应用那些我们设计的 `css` 变量了。
这一块可以参考下方链接中的`动态调整系统主题色(4)`中的`CssVar`方案,里面也有和 `tailwindcss` 相结合的部分,也欢迎阅读`动态调整web系统主题` 系列文章,并与在下进行探讨。
## 动态调整主题参考链接
1. [动态调整web系统主题? 看这一篇就够了](https://icebreaker.top/articles/2021/12/18-flexible-theme)
2. [动态调整web主题(2) 萃取篇](https://icebreaker.top/articles/2022/1/15-custom-theme-2)
3. [动态调整web主题(3): 基于tailwindcss插件的主题色生成方案](https://icebreaker.top/articles/2022/9/26-custom-theme-3)
4. [动态调整系统主题色(4): CssVar 与 Variant 方案的探索](https://icebreaker.top/articles/2023/10/5-custom-theme-4)
## 参考示例
微信上搜索 `tailwind`(未交 `30` 元个人资质费用,已无法搜索),进入小程序即可,小程序码:

实现源代码详见: [weapp-tailwindcss/tailwindcss-weapp](https://github.com/sonofmagic/weapp-tailwindcss/tree/main/tailwindcss-weapp)
---
## 构建以及引入外部组件
## 前言
我们在日常的开发中,经常会去使用和封装各种各样的组件库。有些是开源的,第三方开发的UI库,有些是我们开发人员给自己的特定的业务封装的UI库。其中很多情况其实是以流行的 `开源UI库(或者fork的改版)` + `自己封装的业务组件为主的`
`开源UI库` 它们的样式相对来说是独立于整套系统的,比如它们的样式都是 `ant-`,`el-` 开头的,一般引入之后不会和原先系统里的样式产生冲突。而 `自己封装的业务组件`,由于往往和系统高度绑定也没有这样的问题。
那么如何用 `tailwindcss` 来构建/发布和引入自己封装的业务组件呢?
## 构建组件
### 核心思想
首先我必须重点把本篇文章的核心思想预先抛出:
`tailwindcss` 只是一个`css`生成器,它只是帮你按照一定的规则,从你的源代码中匹配字符串去生成`css`。所以在用它去构建组件的时候,一定要去思考你用 `tailwindcss` 生成的 `css` 的影响范围,因为大部分用 `tailwindcss` 都是默认全局应用的。但是你在组件里面的自定义样式很多情况下,是没有必要的。
根据这个核心思想,我们就可以知道在封装组件时可行和不可行的方式了,大致如下:
### 可行方案
1. `custom css selector` + `Functions & Directives`
2. `add prefix` (添加前缀)
3. `add scoped` (像 `vue` 的 `scoped` 一样添加 data-v-[hash] 类似的自定义属性,然后去修改css选择器)
4. 不打包方案 (不构建产物,直接发布,然后在项目里安装,再提取 `node_modules` 里制定的文本重新生成。)
### 不可行方案
1. module css 这会去修改 css 选择器。
## 可行方案详解
这里我写了2个`demo`分别是 `react` 和 `vue`,其中下方代码以 `vue` 为示例,`react`示例见下方的 `构建demo链接`
### custom css selector + Functions & Directives
这种方案其实非常的传统,仅仅使用到了 `tailwindcss` 中 `@apply` 和 `theme` 等等指令的功能。
比如我们有个组件 `ApplyButton.vue`,它的模板,样式和独立的 `tailwind.config.js` 分别如下所示:
```html
```
```css
@config 'tailwind.config.js';
@tailwind utilities;
.apply-button {
@apply text-white p-4 rounded;
background-color: theme("colors.sky.600")
}
```
```js
const path = require('node:path')
/** @type {import('tailwindcss').Config} */
export default {
content: [path.resolve(__dirname, './index.vue')],
// ...
}
```
然后在打包的时候,以这个文件或者导出文件(`index.ts`) 为打包入口即可。
这样它的产物css中,选择器由于是你自己定义的,就能尽可能保证它是独一无二的。
它对应的`css`产物为:
```css
.apply-button {
border-radius: 0.25rem;
--tw-bg-opacity: 1;
background-color: rgb(2 132 199 / var(--tw-bg-opacity));
padding: 1rem;
--tw-text-opacity: 1;
color: rgb(255 255 255 / var(--tw-text-opacity));
}
```
### add prefix
这个也很好理解,前缀嘛,各个UI库都是这样搞的,我们就可以创建出以下的代码:
```html
```
```js
const path = require('node:path')
/** @type {import('tailwindcss').Config} */
export default {
prefix: 'ice-',
content: [path.resolve(__dirname, './index.vue')],
}
```
它对应的`css`产物为:
```css
.ice-rounded {
border-radius: 0.25rem;
}
.ice-bg-sky-600 {
--tw-bg-opacity: 1;
background-color: rgb(2 132 199 / var(--tw-bg-opacity));
}
.ice-p-4 {
padding: 1rem;
}
.ice-text-white {
--tw-text-opacity: 1;
color: rgb(255 255 255 / var(--tw-text-opacity));
}
```
### add scoped
这个就是通过同时添加html标签属性和修改css选择器来做的了:
```html
```
这里仅仅给 `style` 加了一个 `scoped` 属性
```js
const path = require('node:path')
/** @type {import('tailwindcss').Config} */
export default {
content: [path.resolve(__dirname, './index.vue')],
}
```
`css` 生成结果为:
```css
.rounded[data-v-10205a53] {
border-radius: 0.25rem;
}
.bg-sky-600[data-v-10205a53] {
--tw-bg-opacity: 1;
background-color: rgb(2 132 199 / var(--tw-bg-opacity));
}
.p-4[data-v-10205a53] {
padding: 1rem;
}
.text-white[data-v-10205a53] {
--tw-text-opacity: 1;
color: rgb(255 255 255 / var(--tw-text-opacity));
}
```
### 不打包
以上三种方式总结一下,都是通过在选择器上下功夫来制作组件库的,而且它们都有一个打包的过程,即 `src`->`dist` 然后发布 `dist`
可是这第四种方案就不怎么一样了: 核心就是 `不打包`
即我们写好组件之后,直接把 `npm`的入口文件,指向 `src` ,然后直接把里面的组件发布(比如直接发布 `vue`组件)
这种情况下,你需要让你在 `node_modules` 里的组件再次经受一遍 `js` 的处理,比如 `vue sfc compiler`,`babel`,`swc`等等。
同时你也需要配置你项目里的 `tailwind.config.js` 去提取你 `node_modules` 里的组件源代码内容:
```diff
module.exports = {
content: [
'./index.html',
'./src/**/*.{html,js,ts,jsx,tsx,vue}',
+ './node_modules/mypkg/src/components/**/*.{html,js,ts,jsx,tsx,vue}'
]
}
```
这样才能重新提取生成 `css` 在项目主`css chunk`里。
## 构建demo链接
## 相关 issues
---
## CSS 单位转化
## rem 转 rpx (或 px)
在 [rem 转 rpx (或 px)](/docs/quick-start/rem2rpx) 章节,我们做了 `CSS` 中 `rem` 转化成 `px` / `rpx` 的方式。
但是除了 [rem 转 rpx (或 px)](/docs/quick-start/rem2rpx),我们可能也有 `px 转 rpx` 的需求,这种情况实际上也很容易就能做到。
## px 转 rpx
### 4.3.0 以后
从 `weapp-tailwindcss@4.3.0` 开始,我们内置了 [`postcss-pxtransform`](https://www.npmjs.com/package/postcss-pxtransform) 插件,提供了开箱即用的 `px` 转 `rpx` 的方式。
只需传入配置项:
```js
// vite
UnifiedViteWeappTailwindcssPlugin({
// ...other-options
px2rpx: true
})
// webpack
const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
new UnifiedWebpackPluginV5({
// ...other-options
px2rpx: true
})
```
只需传入一个 `true`,你写的所有的 `px` 都会被 `1:1` 的转换成 `rpx`,比如 `10px` -> `10rpx`
当然这个选项也可以传入一个 `object`, 这个默认值和参数,可以参考 [`postcss-pxtransform`](https://www.npmjs.com/package/postcss-pxtransform) 插件。
### 4.3.0 以前
这里我们使用 [`postcss-pxtransform`](https://www.npmjs.com/package/postcss-pxtransform) 这个 `postcss` 插件来做。
> [`postcss-pxtransform`](https://www.npmjs.com/package/postcss-pxtransform) 由京东团队出品,应该是目前质量最高的 `px` 转 `rpx` 插件,而且已经被内置在了 `tarojs` 框架内
#### 安装插件
```bash npm2yarn
npm i -D postcss-pxtransform
```
#### 注册到 postcss 配置中
```js title="postcss.config.js"
module.exports = {
plugins: {
'tailwindcss': {},
'autoprefixer': {},
// highlight-start
// 下方为 px 转 rpx 区域
'postcss-pxtransform': {
platform: 'weapp',
// 根据你的设计稿宽度进行配置
// 可以传入一个 function
// designWidth (input) {
// if (input.file.replace(/\\+/g, '/').indexOf('@nutui/nutui-taro') > -1) {
// return 375
// }
// return 750
// },
designWidth: 750, // 可以设置为 375 等等来应用下方的规则,
deviceRatio: {
640: 2.34 / 2,
// 此时应用到的规则,代表 1px = 1rpx
750: 1,
828: 1.81 / 2,
// 假如你把 designWidth 设置成 375 则使用这条规则 1px = 2rpx
375: 2 / 1,
},
},
// highlight-end
},
}
```
这样就能进行转化了,此时假如你写 `w-[20px]` 这种 `class` 它最终生效的样式会经过 `postcss-pxtransform` 转化,转变为 `width: 20rpx`, 当然这取决于你传入插件的配置,比如设计稿宽度 (`designWidth`)
你可以在 [taro 官网的设计稿及尺寸单位章节内](https://docs.taro.zone/docs/size) 查看这个插件的所有用法。
另外,假如你要禁止单个文件 `px` 转 `rpx`,可以在样式表文件内头部,添加 `/*postcss-pxtransform disable*/` 这样的注视,禁用该文件 `px` 转 `rpx`。
---
## Nodejs API
> 版本 2.11.0+ , 此为高阶 `api`,使用起来有难度,不适合新手,假如你不清楚你在做什么,请使用 `webpack/vite/gulp` 插件
有时候,我们不一定会使用 `webpack/vite/gulp`,可能是直接使用 `nodejs` 去构建应用,或者封装更高阶的工具,这时候可以使用`api`去转义你的应用。
## 如何使用
```js
// mjs or
// cjs
const { createContext } = require('weapp-tailwindcss/core')
async function main(){
// createContext 可传入参数,类型为 UserDefinedOptions
const ctx = createContext()
// 3.1.0 开始 api 都是异步的,为 rust 工具链做准备
const wxssCode = await ctx.transformWxss(rawWxssCode)
const wxmlCode = await ctx.transformWxml(rawWxmlCode)
const jsCode = await ctx.transformJs(rawJsCode)
// 传入参数和输出结果均为 字符串 string
// 然后你就可以根据结果去复写你的文件了
}
main()
```
:::tip
有一点要特别注意,在使用 `ctx.transformJs` 的时候,一定要确保 `tailwindcss` 已经执行完毕了!也就是说对应的 `postcss` 执行完毕。
因为 `js` 的转义依赖 `tailwindcss` 的执行结果,然后根据它,再去从你的代码中找到 `tailwindcss` 提取出的字符串,再进行处理的。
假如此时 `tailwindcss` 还没有执行,则插件就只能获取到一个 **空的** 提取字符串集合,这就无法进行匹配,从而导致你写在 `js` 里的类名转义失效。
比如这种情况:
```js
// index.js
const classNames = ['mb-[1.5rem]']
```
另外使用此种方式,编译缓存需要自行处理,且暂时没有类名的压缩与混淆功能
:::
---
## uni-app HbuilderX 使用方式
## 默认使用方式
> 配置会稍微复杂一些,这里推荐直接使用或者参考模板: [uni-app-vue3-tailwind-hbuilder-template](https://github.com/sonofmagic/uni-app-vue3-tailwind-hbuilder-template) 或者 [若依移动端 (Gitee 地址)](https://gitee.com/sonofmagic/RuoYi-App)
### tailwind.config.js
注意: 在使用 `hbuilderx` 进行开发时,由于目录结构和启动项的不同,你必须要给你 `tailwind.config.js` 传入**绝对路径**:
```js title="tailwind.config.js"
const path = require("path");
const resolve = (p) => {
return path.resolve(__dirname, p);
};
/** @type {import('tailwindcss').Config} */
module.exports = {
// 注意此处,一定要 `path.resolve` 一下, 传入绝对路径
// 你要有其他目录,比如 components,也必须在这里,添加一下
content: ["./index.html", "./pages/**/*.{html,js,ts,jsx,tsx,vue}"].map(resolve),
// ...
corePlugins: {
// 跨多端可以 h5 开启,小程序关闭
preflight: false,
},
};
```
### vite.config.[tj]s
另外使用 `vite.config.[tj]s` 中注册 `tailwindcss` 时,也要传入绝对路径:
```js title="vite.config.[tj]s"
// 注意: 打包成 h5 和 app 都不需要开启插件配置
const isH5 = process.env.UNI_PLATFORM === "h5";
const isApp = process.env.UNI_PLATFORM === "app";
const WeappTailwindcssDisabled = isH5 || isApp;
const resolve = (p) => {
return path.resolve(__dirname, p);
};
export default defineConfig({
plugins: [
uni(),
uvwt({
rem2rpx: true,
disabled: WeappTailwindcssDisabled,
// 由于 hbuilderx 会改变 process.cwd 所以这里必须传入当前目录的绝对路径
tailwindcssBasedir: __dirname
})
],
css: {
postcss: {
plugins: [
require("tailwindcss")({
// 注意此处,手动传入你 `tailwind.config.js` 的绝对路径
config: resolve("./tailwind.config.js"),
}),
require("autoprefixer"),
],
},
},
});
```
`hbuilderx` 正式版本的 `vue2` 项目,由于使用 `webpack4` 和 `postcss7`,所以只能使用本插件的 `weapp-tailwindcss/webpack4` 版本, 详见[uni-app-vue2-tailwind-hbuilder-template](https://github.com/sonofmagic/uni-app-vue2-tailwind-hbuilder-template)
或者下方也有一种 `Hack hbuilderx vue2 Way` 来在 `hbuilderx` `vue2` 项目中,使用 `webpack5` 和 `postcss8`
## Hbuilderx 与 uni-app cli 环境汇总
首先,你需要知道你的项目究竟使用的是什么打包工具,截止今天 `2023/12/18` 目前如下所示:
| | webpack | vite | postcss |
| ---------------- | -------- | ---- | -------- |
| hbuilderx vue2 | webpack4 | x | postcss7 |
| uni-app cli vue2 | webpack5 | x | postcss8 |
| hbuilderx vue3 | x | √ | postcss8 |
| uni-app cli vue3 | x | √ | postcss8 |
也就是说,目前 `hbuilderx vue2` 的项目是最老的,无法使用最新版本的 `tailwindcss`,其他都可以使用。
## hbuilderx vue2 webpack4 postcss7 版本模板
如果你实在必须在 `hbuilderx vue2` 的项目中使用 `tailwindcss`,那么你可以使用下面的方法来使用 `tailwindcss`
详见 [uni-app-vue2-tailwind-hbuilder-template](https://github.com/icebreaker-trash/uni-app-vue2-tailwind-hbuilder-template)
## Hack hbuilderx vue2 Way
:::caution
以下方式为全局 Hack, 可能会在 `hbuilderx` 升级后出现问题
:::
`hbuilderx` 和 `hbuilderx alpha` 新建的 `vue2` 项目,发现它们的 `webpack` 版本被锁死在了 **`4`** ,我又用 `cli` 创建了一个 `vue2` 项目,发现已经是 `webpack5` 了,看起来只有 `cli` 创建的项目,会被默认升级 `webpack5`。
当然这并不意味着 `hbuilderx` 创建的 `vue2` 项目无法使用最新的这个插件,我们可以强行升级 `HBuilderX/plugins/uniapp-cli` 中的依赖,使得它适配 `webpack5`
> Macos uniapp-cli 路径在 /Applications/HBuilderX.app/Contents/HBuilderX/plugins/uniapp-cli
>
> Windows 的路径应该也在类似的地方,记得要先下载 vue2 的编译器,这个文件夹才有
来到 `uniapp-cli` 这个项目路径,执行 `yarn upgradeInteractive --latest` 升级项目依赖,重点升级 `@vue/cli-*` 相关包到 `5`
这时候 `webpack` 已经被升级到 `5` 版本了,然后你升级其他的 `loader` 到适配 `webpack5` 的版本(通常是最新版本)
再安装 `postcss` 和 `postcss-loader` 的最新版本,这时候你就把整个 `uni-app vue2` 项目的 `hbuilderx` 内置 `cli` 从 `webpack4`,`postcss7`变为了 `webpack5`,`postcss8` 了
不过代价是什么呢?那就是,这项改动是全局的!
你要想恢复设置,那只有重新安装 `uni-app vue2` 编译插件,或者重新安装整个 `hbuilderx`,所以这里还是推荐使用 `cli` 方式去创建项目,保证一个项目一个编译模式,你要节省空间就用 `pnpm`, 想用什么版本编译就用什么版本。
## 视频演示
---
## mpx (原生增强)
在 `vue.config.js` 中注册:
```js title="vue.config.js"
const { defineConfig } = require('@vue/cli-service')
const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
module.exports = defineConfig({
// other options
configureWebpack(config) {
config.plugins.push(
new UnifiedWebpackPluginV5({
rem2rpx: true,
})
)
}
})
```
## 引入 Tailwind CSS 样式
Tailwind 的底层样式需要显式导入。不同主版本的包结构略有差异:
### Tailwind CSS v3.x
仍然可以直接引用 Tailwind 提供的底层样式文件(带 `.css` 扩展名):
```html title="src/app.mpx"
```
### Tailwind CSS v4.x
v4 官方改用了全新的 CSS 包结构,推荐直接引入 `weapp-tailwindcss` 提供的聚合样式文件:
```html title="src/app.mpx"
```
这样即可获得预置的 base / components / utilities,同时避免 `postcss-import` 误解析到 JS 入口导致构建报错。
## mpx 中的 vscode tailwindcss 智能提示缺失设置
我们知道 `tailwindcss` 最佳实践,是要结合 `vscode`/`webstorm`提示插件一起使用的。
假如你遇到了,在 `vscode` 的 `mpx` 文件中,编写 `class` 没有出智能提示的情况,可以参考以下步骤。
这里我们以 `vscode` 为例:
接着找到 `Tailwind CSS IntelliSense` 的 `扩展设置`
在 `include languages`,手动标记 `mpx` 的类型为 `html`

保存设置,再去`mpx`文件里写`class`的时候,智能提示就出来啦。
---
## 原生开发(打包方案)
:::warning
注意!这是原生开发(**打包方案**),假如你需要纯原生方案,请查看 [快速开始(纯原生)](/docs/quick-start/native/install)
:::
> 由于原生小程序没有 `webpack/vite/gulp` 工具链暴露出来,所以我们要添加这一套机制,来整个前端社区接轨,以此来实现更强大的功能。
:::tip
给原生小程序加入编译时这块 `webpack/vite/gulp` 等等工具,思路都是一样的,然而实现起来比较复杂,损耗精力,在此不提及原理。
更改模板工具链流程前,请确保你比较熟悉工具链开发(到我这样的水平就差不多了)。
另外这些模板,只需要稍微改一下产物后缀,添加 `tailwind.config.js` 的 `content` 就可以适配百度,头条,京东...各个平台。
:::
## gulp 模板
模板项目 [weapp-tailwindcss-gulp-template(gulp打包)](https://github.com/sonofmagic/weapp-tailwindcss-webpack-plugin/tree/main/demo/gulp-app)
## webpack5 模板
模板项目 [weapp-native-mina-tailwindcss-template(webpack打包)](https://github.com/sonofmagic/weapp-native-mina-tailwindcss-template)
## 组件样式的隔离性
:::tip
发现很多用户,在使用原生开发的时候,经常会问,为什么样式不生效。
这可能有以下几个原因:
1. 代码文件不在 `tailwind.config.js` 的 `content` 配置内
2. 原生小程序组件是默认开启 **组件样式隔离** 的,默认情况下,自定义组件的样式只受到自定义组件 wxss 的影响。而 `tailwindcss` 生成的工具类,都在 `app.wxss` 这个全局样式文件里面。不属于组件内部,自然不生效。
这时候可以使用:
```js
/* 组件 custom-component.js */
Component({
options: {
addGlobalClass: true,
}
})
```
来让组件应用到 `app.wxss` 里的样式。
[微信小程序相关开发文档](https://developers.weixin.qq.com/miniprogram/dev/framework/custom-component/wxml-wxss.html#%E7%BB%84%E4%BB%B6%E6%A0%B7%E5%BC%8F%E9%9A%94%E7%A6%BB)
:::
## vscode tailwindcss 智能提示设置
我们知道 `tailwindcss` 最佳实践,是要结合 `vscode`/`webstorm`提示插件一起使用的。
假如你遇到了,在 `vscode` 的 `wxml` 文件中,编写 `class` 没有出智能提示的情况,可以参考以下步骤。
这里我们以 `vscode` 为例:
1. 安装 [`WXML - Language Services 插件`](https://marketplace.visualstudio.com/items?itemName=qiu8310.minapp-vscode)(一搜 wxml 下载量最多的就是了)
2. 安装 [`Tailwind CSS IntelliSense 插件`](https://marketplace.visualstudio.com/items?itemName=bradlc.vscode-tailwindcss)
接着找到 `Tailwind CSS IntelliSense` 的 `扩展设置`
在 `include languages`,手动标记 `wxml` 的类型为 `html`

智能提示就出来了:

---
## Rax (react)
在根目录下创建一个 `build.plugin.js` 文件,然后在 `build.json` 中注册:
```json title="build.json"
{
"plugins": [
"./build.plugin.js"
],
}
```
回到 `build.plugin.js`
```js title="build.plugin.js"
const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
module.exports = ({ context, onGetWebpackConfig }) => {
onGetWebpackConfig((config) => {
config.plugin('UnifiedWebpackPluginV5').use(UnifiedWebpackPluginV5, [
{
rem2rpx: true,
},
]);
});
};
```
---
## Taro (所有框架)
目前 Taro v4 同时支持了 `Webpack` 和 `Vite` 进行打包编译,`weapp-tailwindcss` 这 `2` 者都支持,但是配置有些许的不同
:::caution
假如你写了 `tailwindcss` 工具类不生效,可能是由于微信开发者工具默认开启了 `代码自动热重载` 功能,关闭它即可生效。
假如你和 `NutUI` 一起使用,或者启用了 `@tarojs/plugin-html` 插件,请一定要查看这个[注意事项](/docs/issues/use-with-nutui)!
:::
下列配置同时支持 `taro` 的 `react` / `preact` / `vue2` / `vue3` 所有框架
## 使用 Webpack 作为打包工具
### 注册插件
在项目的配置文件 `config/index` 中注册:
```js title="config/index.[jt]s"
const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
// 假如你使用 ts 配置,则使用下方 import 的写法
// import { UnifiedWebpackPluginV5 } from 'weapp-tailwindcss/webpack'
{
// 找到 mini 这个配置
mini: {
// postcss: { /*...*/ },
// 中的 webpackChain, 通常紧挨着 postcss
webpackChain(chain, webpack) {
// 复制这块区域到你的配置代码中 region start
// highlight-start
chain.merge({
plugin: {
install: {
plugin: UnifiedWebpackPluginV5,
args: [{
// 这里可以传参数
rem2rpx: true,
}]
}
}
})
// highlight-end
// region end
}
}
}
```
然后正常运行项目即可,相关的配置可以参考模板 [taro-react-tailwind-vscode-template](https://github.com/sonofmagic/taro-react-tailwind-vscode-template)
:::info
`weapp-tailwindcss/webpack` 对应的插件 `UnifiedWebpackPluginV5` 对应 `webpack@5`
`weapp-tailwindcss/webpack4` 对应的插件 `UnifiedWebpackPluginV4` 对应 `webpack@4`
在使用 `Taro` 时,检查一下 `config/index` 文件的配置项 `compiler`,来确认你的 `webpack` 版本,推荐使用 `'webpack5'`
另外假如你使用了 [`taro-plugin-compiler-optimization`](https://www.npmjs.com/package/taro-plugin-compiler-optimization) 记得把它干掉。因为和它一起使用时,它会使整个打包结果变得混乱。详见 [issues/123](https://github.com/sonofmagic/weapp-tailwindcss/issues/123) [issues/131](https://github.com/sonofmagic/weapp-tailwindcss/issues/131)
还有 `taro` 的 `prebundle` 功能老是出错,最近更新之后,由于 `prebundle` 默认开启,有时候连 `taro cli` 初始化的模板项目都跑不起来,假如遇到问题找不到原因,可以尝试关闭这个配置。
:::
## 使用 Vite 作为打包工具
由于 `taro@4` 的 `vite` 版本,目前加载 `postcss.config.js` 配置是失效的,所以我们目前暂时只能使用内联 `postcss` 插件的写法
### 在 `config/index.ts` 中注册插件
```ts title="config/index.[jt]s"
const baseConfig: UserConfigExport<'vite'> = {
// ... 其他配置
// highlight-start
compiler: {
type: 'vite',
vitePlugins: [
{
// 通过 vite 插件加载 postcss,
name: 'postcss-config-loader-plugin',
config(config) {
// 加载 tailwindcss
if (typeof config.css?.postcss === 'object') {
config.css?.postcss.plugins?.unshift(tailwindcss())
}
},
},
uvtw({
// rem转rpx
rem2rpx: true,
// 除了小程序这些,其他平台都 disable
disabled: process.env.TARO_ENV === 'h5' || process.env.TARO_ENV === 'harmony' || process.env.TARO_ENV === 'rn',
// 由于 taro vite 默认会移除所有的 tailwindcss css 变量,所以一定要开启这个配置,进行css 变量的重新注入
injectAdditionalCssVarScope: true,
})
] as Plugin[] // 从 vite 引入 type, 为了智能提示
},
// highlight-end
// ... 其他配置
}
```
`tailwindcss` 即可注册成功,正常使用了
这段代码的意思为,在 `vite` 里注册 `postcss` 插件和 `vite` 插件
> `vite.config.ts` 只有在运行小程序的时候才会加载,`h5` 不会,所以只能通过这种方式进行 `小程序` + `h5` 双端兼容
## 视频演示
---
## uni-app cli vue3 vite
:::warning
这是 `uni-app cli` 创建的项目的注册方式,如果你使用 `HbuilderX`,应该查看 [uni-app HbuilderX 使用方式](/docs/quick-start/frameworks/hbuilderx)
:::
## 注册插件
创建完成后,快速上手中的准备工作都完成之后,就可以便捷的注册了:
```js title="vite.config.[jt]s"
export default defineConfig({
// uni 是 uni-app 官方插件, uvtw 一定要放在 uni 后,对生成文件进行处理
plugins: [uni(),uvwt()],
css: {
postcss: {
plugins: [
// require('tailwindcss')() 和 require('tailwindcss') 等价的,表示什么参数都不传,如果你想传入参数
// require('tailwindcss')({} <- 这个是postcss插件参数)
require('tailwindcss'),
require('autoprefixer')
],
},
},
});
```
这里只列举了插件的注册,包括`postcss`配置完整的注册方式,参考配置项文件链接:
## 创建项目参考
`uni-app vite` 版本是 `uni-app` 最新的升级,它使用 `vue3` 的语法。
你可以通过 `cli` 命令创建项目 ([参考官网文档](https://uniapp.dcloud.net.cn/quickstart-cli.html)):
- 创建以 javascript 开发的工程(如命令行创建失败,请直接访问 gitee 下载模板)
```bash
npx degit dcloudio/uni-preset-vue#vite my-vue3-project
```
- 创建以 typescript 开发的工程(如命令行创建失败,请直接访问 gitee 下载模板)
```bash
npx degit dcloudio/uni-preset-vue#vite-ts my-vue3-project
```
> gitee 地址见上方的 `参考官网文档` 链接,点击跳转到 uni-app 官网即可
## 视频演示
---
## 🔥 uni-app x
目前 `weapp-tailwindcss` 从 `4.2.0` 版本开始,插件已经支持 `uni-app-x` 同时构建包括 `web`,`小程序`, `安卓`,`IOS`,`鸿蒙` 五端项目
## 创建工具类
在项目中创建 `shared.js` 文件,用于存放一些工具函数:
```js title="shared.js"
const path = require('node:path')
function r(...args) {
return path.resolve(__dirname, ...args)
}
module.exports = {
r,
}
```
## 注册插件
创建 `vite.config.ts` 文件,注册插件:
> 这里特别注意 `uniAppX` 是从 `weapp-tailwindcss/presets` 这个预设中导出的
```js title="vite.config.[jt]s"
export default defineConfig({
plugins: [
uni(),
UnifiedViteWeappTailwindcssPlugin(
uniAppX({
base: __dirname,
rem2rpx: true,
}),
),
],
css: {
postcss: {
plugins: [
tailwindcss({
config: r('./tailwind.config.js'),
}),
]
}
}
});
```
## 更改 tailwindcss 配置
使用绝对路径,包括所有的提取文件
```js title="tailwind.config.js"
const { r } = require('./shared')
/** @type {import('tailwindcss').Config} */
module.exports = {
content: [
r('./pages/**/*.{uts,uvue}'),
r('./components/**/*.{uts,uvue}')
],
corePlugins: {
preflight: false,
},
}
```
## 现成模板可以直接使用或者参考
https://github.com/icebreaker-template/uni-app-x-hbuilderx
使用方式详见项目中的 `README.md`
---
## uni-app cli vue2 webpack
:::warning
这是 `uni-app cli` 创建的项目的注册方式,如果你使用 `HbuilderX`,应该查看 [uni-app HbuilderX 使用方式](/docs/quick-start/frameworks/hbuilderx)
:::
:::tip
截止到 (2023/09/08),目前所有的 `uni-app vue2 cli` 项目的 `webpack` 版本,已经切换到了 `webpack@5`,`@vue/cli@5`,`postcss@8` 了
另外如果你有旧有的 `uni-app webpack4` 项目需要迁移到 `webpack5`,可以看这篇 [旧有uni-app项目升级webpack5指南](/docs/upgrade/uni-app)
:::
```js title="vue.config.js"
const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
/**
* @type {import('@vue/cli-service').ProjectOptions}
*/
const config = {
// some option...
// highlight-start
configureWebpack: (config) => {
config.plugins.push(
new UnifiedWebpackPluginV5({
rem2rpx: true,
})
)
}
// highlight-end
// other option...
}
module.exports = config
```
这样所有的配置便完成了!赶紧启动你的项目试试吧!
---
## tailwindcss 多上下文与独立分包
你看过动漫《百兽王》吗?《百兽王》的主人公是五个飞行员,他们分别驾驶黑、红、青、黄、绿五头机器狮,它们平时可以单独进行作战,遇到强敌时,也能进行五狮合体,成为巨大机器人“百兽王”。
同样,在日常开发中,我们经常遇到这样的问题,一个很大的程序,它有很多个独立的部分组成,每一个部分可以单独运行,也有独立的入口,相互之间没有任何的依赖,但是它们在同一个项目/任务里进行构建。
在这种场景下,去使用 `tailwindcss` 就往往需要去创建多个上下文,让这些上下文各自去管理我们程序中的指定的一块区域。
当然我写到这,相信大家也啥都没看懂,于是我搬出一个小程序中,独立分包的示例,来让大家理解这种思想。
## 什么是独立分包
独立分包是小程序中一种特殊类型的分包,可以独立于主包和其他分包运行。从独立分包中页面进入小程序时,不需要下载主包。当用户进入普通分包或主包内页面时,主包才会被下载。
独立分包属于分包的一种。普通分包的所有限制都对独立分包有效。独立分包中插件、自定义组件的处理方式同普通分包。此外,使用独立分包时要注意:
1. 独立分包中不能依赖主包和其他分包中的内容,包括 js 文件、template、wxss、自定义组件、插件等(使用 分包异步化 时 js 文件、自定义组件、插件不受此条限制)
2. 主包中的 `app.wxss` 对独立分包无效,应避免在独立分包页面中使用 `app.wxss` 中的样式;
3. App 只能在主包内定义,独立分包中不能定义 App,会造成无法预期的行为;
4. 独立分包中暂时不支持使用插件。
> 更多信息详见 [微信独立分包官方文档](https://developers.weixin.qq.com/miniprogram/dev/framework/subpackages/independent.html)
---
这里要特别注意第二条: **主包中的 `app.wxss` 对独立分包是无效的!!!**
在我之前提供的`tailwindcss`小程序模板的示例中,所有 `tailwindcss` 生成的 `wxss` 工具类都是在主包里共用的 (`app.wxss`),这在大部分情况下运转良好,然而这在独立分包场景下,是不行的!因为主包的样式无法影响到独立分包。
那么应该怎么做才能解决这个问题呢?
## 创建与配置示例
这里笔者先以 `taro@3.6.7` 和 `weapp-tailwindcss@2.5.2` 版本的项目作为示例。
首先配置好 `weapp-tailwindcss` 的配置,然后在 `config/index.js` 中关闭 `prebundle` 功能,因为这在独立分包场景下会报一些未知的错误:
```js
const config = {
compiler: {
prebundle: {
enable: false,
},
type: 'webpack5'
},
// .....
}
```
其次关闭插件对 `tailwindcss css var` 主块的寻址行为:
```js
chain.merge({
plugin: {
install: {
plugin: UnifiedWebpackPluginV5,
args: [{
// 方法1: 不要传 appType
// 注释掉 appType : 'taro'
// 或者方法2: 让所有css chunk 都是 main chunk
// mainCssChunkMatcher: ()=> true
// 2 种选其一即可
}]
}
}
})
```
接下来我们就可以创建一个独立分包 `moduleA`,在里面新建一个 `"pages/index"` 页面,并写入一个只属于 `moduleA` 的独一无二的 `tailwindcss class`,然后在 `app.config.ts` 里注册它:
```js
subpackages: [
{
root: "moduleA",
pages: [
"pages/index",
],
// 下方这个标志位,声明独立分包
independent: true
},
]
```
到这里,准备工作就完成了,接下来就可以设计方案了。
## 单 `tailwindcss` 上下文的方案(不完美不推荐)
这个方案是一个不完美的方案,在这里写出来是为了促进大家对 `tailwindcss` 的理解。
首先在独立分包中,也创建一个 `index.scss` 内容为:
```css
@import 'tailwindcss/base';
@import 'tailwindcss/components';
@import 'tailwindcss/utilities';
```
然后在所有独立分包中的页面引用它,这样打包之后,独立分包里的 `tailwindcss` 样式也就生效了。
然而这种方式有一个巨大的问题,就是它会带来严重的 `css` 冗余。
因为此时 `tailwindcss` 上下文有且仅有一个,它会把在这个项目中,所有提取出来的 `css` 工具类,全部注入到所有的 `@tailwind` 指令里去。`@import 'tailwindcss/utilities'` 这个引入(本质实际上是`@tailwind`指令)一下子膨胀了起来。
这导致了,主包里的 `app.wxss` 里,会包含主包里所有的 `class` + 独立分包里所有的 `class`,而独立分包里的 `index.scss` 里,也包含主包里所有的 `class` + 独立分包里所有的 `class`!
这显然是不可接受的,因为主包是没有必要包含独立分包的 `class`,而独立分包里,也没有必要包含主包里的 `class`! 这只会白白增大打包后`wxss`文件的体积。
所以这个方案需要改进!
## 多 `tailwindcss` 上下文的方案
由于上面那个方案的问题,我们开始改进,就必须要创建多个 `tailwindcss` 上下文。
那么第一步就是要 **`↓`**
### 创建多个 `tailwind.config.js`
比如说我们只有一个独立分包,所以我们创建了2个 `tailwind.config.js`:
1. `tailwind.config.js` 用于主包以及相互依赖的子包
2. `tailwind.config.sub.js` 用于 `moduleA` 这个独立分包
内容如下:
#### 独立分包的上下文配置
```js
// `moduleA` 这个独立分包的 tailwind.config.sub.js
/** @type {import('tailwindcss').Config} */
module.exports = {
// 这里只提取 moduleA 这个独立分包下的文件内容
content: ["./src/moduleA/**/*.{html,js,ts,jsx,tsx}"],
// ....
corePlugins: {
preflight: false
}
}
```
#### 主包以及相互依赖的子包的上下文配置
```js
// 主包以及相互依赖的子包的 tailwind.config.js
/** @type {import('tailwindcss').Config} */
module.exports = {
// https://github.com/mrmlnc/fast-glob
// 这里需要限定范围,不去提取 moduleA 这个独立分包下的文件内容
// 所以后面跟了一个 `!` 开头的路径
content: [
"./src/**/*.{html,js,ts,jsx,tsx}",
// 不提取独立分包里的 class
"!./src/moduleA/**/*.{html,js,ts,jsx,tsx}"],
// ....
corePlugins: {
preflight: false
}
}
```
这样 `2` 个配置文件创建好了,接下来就要通过配置让它们各自在打包中生效。
### `postcss.config.js` 配置
这是非常重要的一块配置,我们需要把 `postcss.config.js` 的配置变成一个函数,这样才能把构建时的上下文传入进来:
```js
const path = require('path')
module.exports = function config(loaderContext) {
// moduleA 下面的所有 scss 文件,都是独立模块的,应用不同的 tailwindcss 配置
const isModuleA = /moduleA[/\\](?:\w+[/\\])*\w+\.scss$/.test(
loaderContext.file
)
// 多个独立子包同理,加条件分支即可
if (isModuleA) {
return {
plugins: {
tailwindcss: {
config: path.resolve(__dirname, 'tailwind.config.sub.js')
},
autoprefixer: {},
}
}
}
return {
plugins: {
// 不传默认取 tailwind.config.js
tailwindcss: {},
autoprefixer: {},
}
}
}
```
通过这种方式,我们成功的创建了 `2` 个不同的 `tailwindcss` 上下文,此时你进行打包之后,会发现
主包里的 `app.wxss` 和独立分包里的 `index.wxss`,里面的内容就已经各归各了,不再相互包含了。
## 尾言
当然,上面只是一种方案,达到这样的目的方式有很多种,比如你可以在运行时去修改 `postcss-loader` 对它进行劫持,或者拆成多个项目,分开构建。
我这篇文章只是抛砖引玉,相信聪明的你们一定可以举一反三的。
## 参考示例
示例见:
---
## 1. 安装与配置 tailwindcss
> 请确保你的 `nodejs` 版本 `^18.17.0 || >=20.5.0`。目前低于 `18` 的长期维护版本(`偶数版本`) 都已经结束了生命周期,建议安装 `nodejs` 的 `LTS` 版本,详见 [nodejs/release](https://github.com/nodejs/release)。
>
> 假如你安装的 `nodejs` 太新,可能会出现安装包不兼容的问题,这时候可以执行安装命令时,使用 `--ignore-engines` 参数进行 `nodejs` 版本的忽略 。
首先安装本插件前,我们需要把 `tailwindcss` 对应的环境和配置安装好。
这里我们参考 `tailwindcss` 官网中 `postcss` 的使用方式进行安装 ([参考链接](https://tailwindcss.com/docs/installation/using-postcss))
## 1. 使用包管理器安装 `tailwindcss`
```bash npm2yarn
# 安装 tailwindcss@3 版本的依赖
npm i -D tailwindcss@3 postcss autoprefixer
```
```bash npm2yarn
# 初始化 tailwind.config.js 文件
npx tailwindcss init
```
:::info
`tailwindcss` 最新版本(`3.x`)对应的 `postcss` 大版本为 `8`,假如你使用像 `uni-app` 或 `taro` 这样的跨端框架,大概率已经内置了 `postcss` 和 `autoprefixer`
:::
## 2. 在项目目录下创建 `postcss.config.js` 并注册 `tailwindcss`
> 注意:这只是比较普遍的注册方式,各个框架很有可能是不同的! 比如 `uni-app vue3 vite` 项目就必须要内联注册 `postcss` 选项! 详见下方的注意事项
```js title="postcss.config.js"
// 假如你使用的框架/工具不支持 postcss.config.js 配置文件,则可以使用内联的写法
module.exports = {
plugins: {
tailwindcss: {},
// 假如框架已经内置了 `autoprefixer`,可以去除下一行
autoprefixer: {},
}
}
```
:::tip 注意事项
`uni-app vite vue3` 项目,必须在`vite.config.ts` 文件中,使用 `postcss` 内联的写法注册插件。相关写法可以参考我的这个模板项目: [uni-app-vite-vue3-tailwind-vscode-template](https://github.com/sonofmagic/uni-app-vite-vue3-tailwind-vscode-template)。
而 `uni-app vue webpack5` 项目中的 `postcss.config.js`,在默认情况下,已经预置很多插件在里面,配置比较繁杂,可以参考这个文件 [uni-app-webpack5/postcss.config.js](https://github.com/sonofmagic/weapp-tailwindcss/blob/main/demo/uni-app-webpack5/postcss.config.js)
:::
## 3. 配置 `tailwind.config.js`
`tailwind.config.js` 是 `tailwindcss` 的配置文件,我们可以在里面配置 `tailwindcss` 的各种行为。
```js title="tailwind.config.js"
/** @type {import('tailwindcss').Config} */
module.exports = {
// 这里给出了一份 uni-app /taro 通用示例,具体要根据你自己项目的目录结构进行配置
// 不在 content 包括的文件内,你编写的 class,是不会生成对应的css工具类的
content: ['./public/index.html', './src/**/*.{html,js,ts,jsx,tsx,vue}'],
// 其他配置项
// ...
corePlugins: {
// 小程序不需要 preflight,因为这主要是给 h5 的,如果你要同时开发小程序和 h5 端,你应该使用环境变量来控制它
preflight: false
}
}
```
## 4. 引入 `tailwindcss`
在你的项目入口引入 `tailwindcss` 使它在小程序全局生效
### uni-app
比如 `uni-app` 的 `App.vue` 文件:
```html title="App.vue"
```
:::warning
千万不要在 `uni.scss` 中去引入 `tailwindcss`, `uni.scss` 本质上走的是 `scss.additionalData`, 它会在每一个 `scss` 文件的开头,都去添加 `uni.scss` 里的文件内容
所以这相当于你每个 `scss`/ `vue` 文件里面,都加了 `tailwindcss` 引入,那 `css` 体积就爆炸了
:::
### Taro
又或者 `Taro` 的 `app.scss` 文件:
```scss title="app.scss"
@import 'tailwindcss/base';
@import 'tailwindcss/components';
@import 'tailwindcss/utilities';
// sass 版本1.25+ 使用 @use
// @use 'tailwindcss/base';
// @use 'tailwindcss/components';
// @use 'tailwindcss/utilities';
// 非 scss 的纯 css 文件,下列写法也是可以生效的
// @tailwind base;
// @tailwind components;
// @tailwind utilities;
```
然后在 `app.ts` 里引入这个样式文件即可。
这样 `tailwindcss` 的安装与配置就完成了,接下来让我们进入第二个环节:安装 `weapp-tailwindcss`。
## 参考链接
[`tailwindcss` 官方配置项](https://tailwindcss.com/docs/configuration)
---
## IDE 智能提示设置
## VS Code
> 首先,确保你已经安装 [`Tailwind CSS IntelliSense 插件`](https://marketplace.visualstudio.com/items?itemName=bradlc.vscode-tailwindcss)
### 让 `Tailwind CSS IntelliSense` 识别 weapp-tailwindcss v4
`tailwindcss-intellisense` 在 v4 中必须看到 `@import "tailwindcss"` 才会将工作区视为 Tailwind 根文件。从 v4.7.10 起,`weapp-tailwindcss` 默认会在构建阶段把这些 `@import 'tailwindcss'` 自动改写成 `@import 'weapp-tailwindcss'`(可通过 `rewriteCssImports: false` 关闭)。这意味着你可以直接在项目入口写 `@import 'tailwindcss';` 以获得 IntelliSense,而插件会在最早的 PostCSS 流程中替换成小程序可用的样式。
如果仍希望与源码解耦,也可以使用 CLI 为 VS Code 生成一个仅供扩展使用的辅助 CSS:
```bash npm2yarn
npx weapp-tailwindcss vscode-entry --css src/app.css
```
- 默认输出在 `.vscode/weapp-tailwindcss.intellisense.css`,其中包含 `@import 'tailwindcss';`、常见的 `@source` globs 以及你传入的 CSS 入口(例如 `src/app.css`)。
- 该文件只用于激活 IntelliSense,不需要、也不应该被打包流程引用。
- 若需自定义文件名或额外的 `@source`,可通过 `--output`、`--source`、`--force` 等参数调整,运行 `npx weapp-tailwindcss vscode-entry --help` 查看全部选项。
- 如果不想生成独立文件,可以直接在真实入口写 `@import 'tailwindcss';`,默认启用的 `rewriteCssImports` 会让 webpack/vite 在 CSS 解析阶段把它映射到 `weapp-tailwindcss`(只影响样式导入,JS/TS `import 'tailwindcss'` 不会被修改)。
保存/重载任意文件后 VS Code 会检测到该辅助文件,从而让 `@import 'weapp-tailwindcss';` 的项目享受到完整的补全、悬浮和跳转体验。
### wxml 的智能提示
我们知道 `tailwindcss` 最佳实践,是要结合 `vscode`/`webstorm`提示插件一起使用的。
假如你遇到了,在 `vscode` 的 `wxml` 文件中,编写 `class` 没有出智能提示的情况,可以参考以下步骤。
这里我们以 `vscode` 为例:
安装 [`WXML - Language Services 插件`](https://marketplace.visualstudio.com/items?itemName=qiu8310.minapp-vscode)(一搜 wxml 下载量最多的就是了)
然后下方提供了 `2` 种方式, `全局设置` 和 `工作区设置`, 根据你的需求仍选其一即可
#### 全局设置
点击 `vscode` 左下角的设置图标里,通过搜索关键词 `tailwindcss` ,找到 `Tailwind CSS IntelliSense` 插件的 `扩展设置`
在 `include languages`,手动标记 `wxml` 的类型为 `html`

智能提示就出来了:

#### 工作区设置
在你的打开的工作区目录的根目录里,创建 `.vscode` 文件夹,然后添加 `settings.json` 内容如下:
```json
{
"tailwindCSS.includeLanguages": {
"wxml": "html"
}
}
```
这样就通过你工作区的 `vscode` 设置,去覆盖了你全局的 `vscode` 设置,也能够达到上图中的效果。
### js,jsx,ts,tsx,vue...这类文件的智能提示
#### 场景
在安装配置好插件后,我们在写代码时,写到那些标签中的 `class=`,`className=`,这种场景时,智能提示一下子就可以出来。
然而我们在写 `js` 代码的时候,很多时候是直接在代码里,去写 `tailwindcss` 字符串字面量,比如:
```jsx
const clsName = 'bg-[#123456] text-[#654321]'
return
```
写这种字符串是没有任何的智能提示的,怎么办呢?
#### 解决方案
这里给出一种基于插件的解决方案:
1. 安装 `clsx`:
```bash npm2yarn
npm i clsx
```
2. 进入你的 `vscode` 设置的 [`settings.json`](https://code.visualstudio.com/docs/getstarted/settings)
在里面加入下方的配置:
```json
{
"tailwindCSS.experimental.classRegex": [
[
"clsx\\(([^)]*)\\)",
"(?:'|\"|`)([^']*)(?:'|\"|`)"
]
]
}
```
这样配置之后,智能提示就出来了:

[Refer link](https://github.com/lukeed/clsx#tailwind-support)
#### 存在问题
这种原理也是依赖正则匹配,即 `Tailwind CSS IntelliSense 插件` 匹配到了当前 `vscode` 活动的文本域中,存在着 `clsx()` 方法这个关键词,所以就把智能提示给注入进去。
所以你这样写就不会生效:
```js
const btn = AAA('')
```
另外,你可以依据这个特性,修改/添加 `"tailwindCSS.experimental.classRegex"` 里的正则,然后自行封装一个方法,用来进行 `tailwindcss` 的智能提示。
## WebStorm
> 和 `vscode` 方式类似,同样使用 `clsx` 函数
1. 确保你的版本大于等于 [WebStorm 2023.1](https://www.jetbrains.com/webstorm/whatsnew/#version-2023-1-tailwind-css-configuration)
2. 打开设置,前往 [Languages and Frameworks | Style Sheets | Tailwind CSS](https://www.jetbrains.com/help/webstorm/tailwind-css.html#ws_css_tailwind_configuration)
3. 添加以下的配置:
```json
{
"experimental": {
"classRegex": ["clsx\\(([^)]*)\\)", "[\"'`]([^\"'`]*).*?[\"'`]"]
}
}
```
> 如果你使用 `class-variance-authority` 的 `cva` 函数,只需再添加 `"cva\\(([^)]*)\\)"` 正则即可。
## HbuilderX
---
## 1. 安装与配置 tailwindcss(Native)
## 前言
很荣幸,我们在 `weapp-tailwindcss@3.2.0` 版本开始,引入了微信小程序原生支持的能力。 (其他平台的原生小程序开发,也非常容易兼容)
接下来让我们看看,如何进行使用吧!
本教程演示的是,使用微信开发者工具创建的原生 `js` 小程序,以及原生 `js` `skyline` 小程序使用 `tailwindcss` 的方式
### 运行环境
请确保你的 `nodejs` 版本 `>=16.6.0`。目前低于 `16` 的长期维护版本(`偶数版本`) 都已经结束了生命周期,建议安装 `nodejs` 的 `LTS` 版本,详见 [nodejs/release](https://github.com/nodejs/release)。
假如你安装的 `nodejs` 太新,可能会出现安装包不兼容的问题,这时候可以执行安装命令时,使用 `--ignore-engines` 参数进行 `nodejs` 版本的忽略 。
## 创建项目
打开微信开发者工具, 点击 `+` 创建一个项目,依次选择:
0. `AppID` 使用测试号
1. 开发模式: `小程序`
2. 后端服务: `不使用云服务`
3. 模板选择: 第二项选择 `基础`
4. 选择 `JS 基础模板`
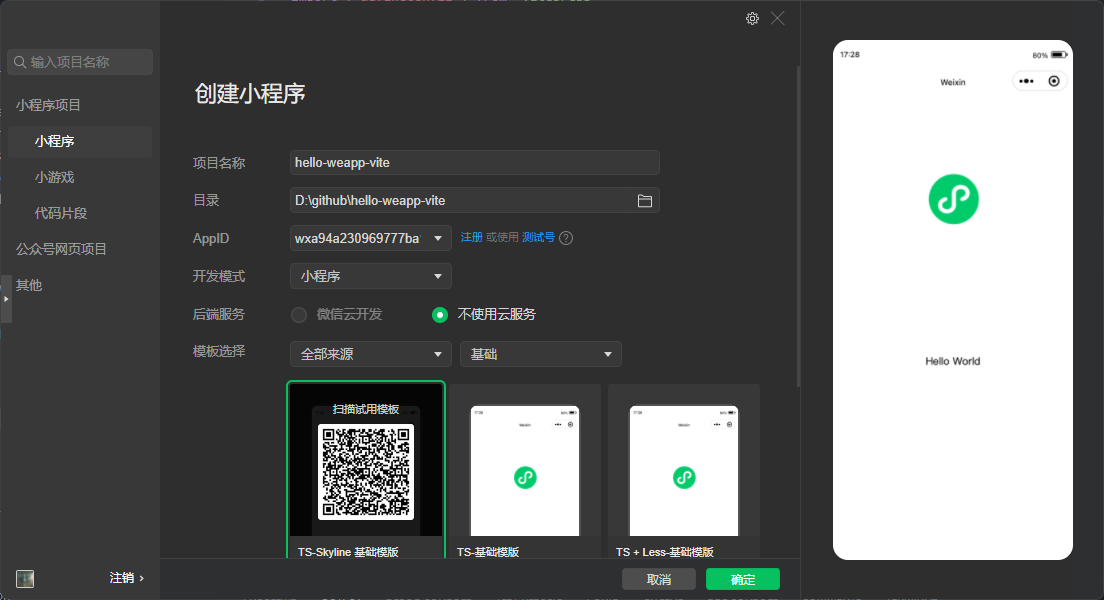
> 使用 JS 基础模板创建的项目,依然可以使用 `Typescript`
首先安装本插件前,我们需要把 `tailwindcss` 对应的环境和配置安装好。
## 0. 初始化 `package.json`
首先,假如你使用原生的 JS 模板创建的项目。
在创建的项目目录下,是没有 `package.json` 文件 (`原生的 TS 模板有这个文件`), 你需要执行命令:
`npm init -y`,快速创建一个 `package.json` 文件在你的项目下
## 1. 使用包管理器安装 `tailwindcss`
然后执行:
```bash npm2yarn
# 安装 tailwindcss@3 版本的依赖
npm i -D tailwindcss@3 postcss autoprefixer
```
```bash npm2yarn
# 初始化 tailwind.config.js 文件
npx tailwindcss init
```
这样 `tailwindcss` 就被安装到你项目本地了
## 2. 配置 `tailwind.config.js`
`tailwind.config.js` 是 `tailwindcss` 的配置文件,我们可以在里面配置 `tailwindcss` 的各种行为。
这里给出了一份 `JS微信小程序` 通用示例,具体要根据你自己项目的目录结构进行配置
```js title="tailwind.config.js"
/** @type {import('tailwindcss').Config} */
module.exports = {
content: [
// 添加你需要提取的文件目录
'components/**/*.{wxml,js,ts}',
'pages/**/*.{wxml,js,ts}',
// 不要使用下方的写法,这会导致 vite 开发时监听文件数量爆炸
// '**/*.{js,ts,wxml}', '!node_modules/**', '!dist/**'
],
// 假如你使用 ts 模板,则可以使用下方的配置
// content: ['miniprogram/**/*.{ts,js,wxml}'],
corePlugins: {
// 小程序不需要 preflight 和 container,因为这主要是给 h5 的,如果你要同时开发小程序和 h5 端,你应该使用环境变量来控制它
preflight: false,
container: false,
}
}
```
## 3. 在项目目录下创建 `postcss.config.js` 并注册 `tailwindcss`
内容如下:
```js title="postcss.config.js"
module.exports = {
plugins: {
tailwindcss: {},
autoprefixer: {},
}
}
```
> 这个文件和 `tailwind.config.js` 平级
## 4. 引入 `tailwindcss`
在你的小程序项目入口 `app.wxss` 文件中,引入 `tailwindcss` 使它在小程序全局生效
```css
@tailwind base;
@tailwind components;
@tailwind utilities;
```
在 `app.wxss` 加入这一段代码之后,微信开发者工具会报错。不用担心,这是因为我们还没有完全配置好。
接下来,赶紧进入下一步,安装 `weapp-tailwindcss` 并运行吧!
---
## 2. 安装这个插件并运行
## 安装插件
在项目目录下,执行:
```bash npm2yarn
npm i -D weapp-tailwindcss weapp-vite
```
这样 `weapp-tailwindcss` 和 `weapp-vite` 就被安装在你的本地了
## 执行初始化命令
在命令行中运行
```sh
npx weapp-vite init
```
这个命令会对现有的原生小程序项目,进行 `weapp-vite` 的初始化
执行后,会发现主要有许多文件改动,`CLI` 主要做了 `3` 件事情:
- 创建 `vite.config.ts` 文件,这个是 `weapp-vite` 和 `vite` 的配置文件
- 修改 `package.json`, 添加 `dev` 和 `build` 开发和构建脚本,还有构建 `npm` 和打开微信开发者工具
- 修改 `project.config.json` 内容,来适配构建产物
- 添加适配 vite 的 `dts` 和 `tsconfig.json`
## 安装所有的依赖包
在执行完成 `weapp-vite init` 初始化命令之后,我们需要在项目里执行一下安装命令:
```bash npm2yarn
npm i
```
## 注册插件
给 `package.json` 添加下列脚本:
```json title="package.json"
{
"scripts": {
"postinstall": "weapp-tw patch"
}
}
```
然后在你的 `vite.config.ts` 里对插件进行注册:
```ts title="vite.config.ts"
export default defineConfig({
// highlight-start
plugins: [
uvwt({
rem2rpx: true,
}),
],
// highlight-end
})
```
## 开始运行
使用 `npm run dev` 进入开发模式, 此模式带有热更新的,主要用于开发
使用 `npm run build` 进行构建
不论是 `npm run dev` 还是 `npm run build`, 他们的构建产物,都在工程目录下的 `dist` 目录
使用微信开发者工具,直接导入工程目录,然后即可预览效果!
> 注意不是导入 `dist` 目录,是你工程的根目录! 通常是 `dist` 的父级目录,不要搞错了!
## 配置好的模板
假如你配置不成功,你可以参考以下模板进行配置文件对比:
[weapp-vite-tailwindcss-template](https://github.com/weapp-vite/weapp-vite/tree/main/apps/weapp-vite-tailwindcss-template)
或者直接执行命令:
```bash npm2yarn
npx weapp-vite create my-app
```
此命令会在当前目录下,创建一个目录名为 `my-app` 的 `weapp-vite` + `weapp-tailwindcss` 集成模板
{/* [vite-native](https://github.com/sonofmagic/weapp-tailwindcss/tree/main/apps/vite-native) */}
{/* [native-weapp-tailwindcss-template](https://github.com/sonofmagic/native-weapp-tailwindcss-template) */}
## 原生组件样式的隔离性
:::tip
发现很多用户,在使用原生开发的时候,经常会问,为什么 `tailwindcss` 样式对自定义组件不生效。
这可能有以下几个原因:
1. 代码文件不在 `tailwind.config.js` 的 `content` 配置内
2. 原生小程序组件是默认开启 **组件样式隔离** 的,默认情况下,自定义组件的样式只受到自定义组件 `wxss` 的影响。而 `tailwindcss` 生成的工具类,都在 `app.wxss` 这个全局样式文件里面。不属于组件内部,自然不生效。
这时候可以在你组件的 `json` 文件配置中,设置下面一行 `styleIsolation` 来开启样式共享:
```json title="custom-component.json"
{
"styleIsolation": "apply-shared"
}
```
> `apply-shared` 表示页面 `wxss` 样式将影响到自定义组件,但自定义组件 `wxss` 中指定的样式不会影响页面;
来让组件应用到 `app.wxss` 里的样式。
更多的文档详见: [微信小程序相关开发文档](https://developers.weixin.qq.com/miniprogram/dev/framework/custom-component/wxml-wxss.html#%E7%BB%84%E4%BB%B6%E6%A0%B7%E5%BC%8F%E9%9A%94%E7%A6%BB)
:::
## 想了解更多 weapp-vite
更多场景和配置,请查看 [weapp-vite 文档网站](https://vite.icebreaker.top/)
---
## 4. rem 转 rpx (或 px)
> 此为可选步骤,根据你自己的需求进行配置。通常此配置的值,是由你拿到的设计稿尺寸决定的。
## 为什么要配置 rem 转 rpx 呢?
这是因为 `tailwindcss` 里面工具类的长度单位,默认都是 `rem`,比如:
```css
.m-4 {
margin: 1rem;
}
.h-4 {
height: 1rem;
}
/*......*/
```
`rem`这个单位在 `h5` 环境下自适应良好,但小程序环境下,我们大部分都是使用 `rpx` 这个 `wxss` 单位来进行自适应,所以就需要把默认的 `rem` 单位转化成 `rpx`。
## 三种转化方式(根据你的需求选其一即可)
## 插件内置 rem 转 rpx 功能 (推荐)
在 `^3.0.0` 版本中,所有插件都内置了 `rem2rpx` 参数,默认不开启,要启用它只需将它设置成 `true` 即可
```js
// vite.config.js
UnifiedViteWeappTailwindcssPlugin({
// ...other-options
// highlight-next-line
rem2rpx: true
})
// webpack
const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
new UnifiedWebpackPluginV5({
// ...other-options
// highlight-next-line
rem2rpx: true
})
```
设置为 `true` 相当于 `rem2rpx` 传入下方这样一个配置对象:
```js
{
// 32 意味着 1rem = 16px = 32rpx
rootValue: 32,
// 默认所有属性都转化
propList: ['*'],
// 转化的单位,可以变成 px / rpx
transformUnit: 'rpx'
}
```
:::tip
为什么 `rootValue` 默认值是 `32`?
这是因为开发微信小程序时, 设计师基本都使用 `iPhone6` 作为视觉稿的标准,此时 `1px = 2rpx`。
然后默认情况下 `1rem = 16px`,所以 `1rem = 16px = 32rpx`。
详见 [WXSS 尺寸单位](https://developers.weixin.qq.com/miniprogram/dev/framework/view/wxss.html#%E5%B0%BA%E5%AF%B8%E5%8D%95%E4%BD%8D) 章节,
:::
当然你也可以自行传入一个 `object` 来进行更多配置,具体的配置项见 [postcss-rem-to-responsive-pixel](https://www.npmjs.com/package/postcss-rem-to-responsive-pixel)
### 优势
这种方式 **最简单**,和插件集成度高,传入一个配置就好了。
## 外置 postcss 插件
首先我们安装 [postcss-rem-to-responsive-pixel](https://www.npmjs.com/package/postcss-rem-to-responsive-pixel)
```bash npm2yarn
npm i -D postcss-rem-to-responsive-pixel
```
安装好之后,把它注册进你的 `postcss.config.js` 即可:
```js title="postcss.config.js"
module.exports = {
plugins: {
tailwindcss: {},
autoprefixer: {},
'postcss-rem-to-responsive-pixel': {
// 32 意味着 1rem = 32rpx
rootValue: 32,
// 默认所有属性都转化
propList: ['*'],
// 转化的单位,可以变成 px / rpx
transformUnit: 'rpx'
// postcss-rem-to-responsive-pixel@6 版本添加了 disabled 参数,用来禁止插件的转化
// disabled: process.env.TARO_ENV === 'h5' || process.env.TARO_ENV === 'rn'
}
}
}
```
:::tip
一些用户在使用 `tarojs` 开发的时候,错误的把 `tailwindcss` 配置在了 `config/index.js` 的 `postcss` 里,导致不生效。
原因实际上是因为 `config/index.js` 的 `postcss`这个配置,只是用来配置 `tarojs` **内置** `postcss` 插件的参数。
要使用 `tailwindcss`,你需要在项目根目录,新建一个 `postcss.config.js`,然后把上面的代码写入进去。
:::
### 优势
这种方式 **最灵活**,你可以自由的决定 `postcss` 插件的加载顺序,也可以按你自己的策略按需加载插件 (比如特定目录下的样式才接受这个插件的转化)
## 外置 tailwindcss 插件
你想缩小一下范围,只把 `tailwindcss` 生成的工具类的单位,从 `rem` 转变为 `rpx`,那么我写的 `tailwindcss preset`: [tailwindcss-rem2px-preset](https://www.npmjs.com/package/tailwindcss-rem2px-preset) 适合你。
同样我们安装它:
```bash npm2yarn
npm i -D tailwindcss-rem2px-preset
```
然后在 `tailwind.config.js` 中,注册这个预设:
```js title="tailwind.config.js"
module.exports = {
presets: [
require('tailwindcss-rem2px-preset').createPreset({
// 32 意味着 1rem = 32rpx
fontSize: 32,
// 转化的单位,可以变成 px / rpx
unit: 'rpx'
})
]
// ...
}
```
这样即可完成 `tailwindcss` 默认工具类的 `rem` 转 `rpx` 的配置了。
### 优势
这种方式受影响范围 **最小**,因为 `preset` 方式处理 `tailwindcss`,不会把你写的其他样式里的 `rem` 转化成 `rpx`
## px 转 rpx
如果你也有 [`px 转 rpx`](/docs/quick-start/css-unit-transform) 的需求,你可以查看 [CSS 单位转化](/docs/quick-start/css-unit-transform) 这个章节。
---
## 2. 安装 weapp-tailwindcss
在项目目录下,执行:
```bash npm2yarn
npm i -D weapp-tailwindcss
# 假如 tailwindcss 在 weapp-tailwindcss 之后安装,可以手动执行一下 patch 方法
# npx weapp-tw patch
```
然后把下列脚本,添加进你的 `package.json` 的 `scripts` 字段里:
```json title="package.json"
"scripts": {
// highlight-next-line
"postinstall": "weapp-tw patch"
}
```
:::caution 使用 pnpm@10+
`pnpm@10` 默认只允许 `onlyBuiltDependencies` 中的包运行生命周期脚本。安装完本插件后,请执行 `pnpm approve-builds weapp-tailwindcss` 将其加入白名单,避免 `postinstall` 的 `weapp-tw patch` 被跳过。
:::
:::info
执行 `weapp-tw patch` 主要是做2件事情
### 1. 给当前你本地的 `tailwindcss` 打上支持 `rpx` 的补丁 (小程序特有单位,非 `web` 标准)。
否则你一旦使用像 `text-[14.43rpx]` 这样的任意值写法,生成出来的 `css` 样式就是 `color: 14.43rpx;`,显然是错误的。
它会被 `tailwindcss` 认为是一种颜色,从而导致生成错误,样式不生效。
详见 [rpx 任意值颜色或长度单位二义性与解决方案](/docs/issues/rpx-ambiguities)
### 2. 暴露 `tailwindcss` 运行上下文给 `webpack`/`vite`/`glup` 插件。
这样就能够在 `js` 中,和 `postcss` 插件进行通信,从而达到共享上下文的效果。
---
而添加上面一段 `npm scripts` 的用途是,利用 `npm hook`, 每次安装包后,都会自动执行一遍 `weapp-tw patch` 这个脚本。
这样即使 `tailwindcss` 更新了版本导致了补丁失效,也会在重新下载后,第一时间被打上。
如果你希望在补丁前“强制刷新 `tailwindcss-patch` 的缓存目录(如 `node_modules/.cache/tailwindcss-patch`)”,可以在命令后附加 `--clear-cache`:
```json title="package.json"
"scripts": {
"postinstall": "weapp-tw patch --clear-cache"
}
```
默认不清理缓存,更加保守稳定;仅当怀疑缓存导致补丁未生效或版本不一致时再开启该参数。
:::
我们已经完成了这些步骤了,最后就是注册这个插件,到各个不同的框架里去,马上就好!
---
## uni-app 条件编译语法糖插件
> 版本需求 2.10.0+
## 这是什么玩意?
在 `uni-app` 里,存在一种类似宏指令的[样式条件编译写法](https://uniapp.dcloud.net.cn/tutorial/platform.html#%E6%A0%B7%E5%BC%8F%E7%9A%84%E6%9D%A1%E4%BB%B6%E7%BC%96%E8%AF%91):
```css
/* #ifdef %PLATFORM% */
平台特有样式
/* #endif */
```
> uni-app `%PLATFORM%` 的所有取值可以参考这个[链接](https://uniapp.dcloud.net.cn/tutorial/platform.html#preprocessor)
在 `weapp-tailwindcss@2.10.0+` 版本中内置了一个 `css-macro` 功能,可以让你的 `tailwindcss` 自动生成带有条件编译的样式代码,来辅助你进行多平台的适配开发,效果类似如下方式:
```html
Web和微信小程序平台蓝色背景
非MP-WEIXIN平台红色背景
微信小程序为蓝色,不是微信小程序为红色
微信小程序为蓝色,不是微信小程序为红色
头条小程序蓝色
```
或者这样的条件样式代码:
```css
/*只在 H5 和 MP-WEIXIN, 背景为蓝色,否则为红色 */
.apply-test-0 {
@apply ifdef-[H5||MP-WEIXIN]:bg-blue-400 ifndef-[H5||MP-WEIXIN]:bg-red-400;
}
/* 自定义 */
.apply-test-1 {
@apply mv:bg-blue-400 -mv:bg-red-400 wx:text-blue-400 -wx:text-red-400;
}
```
让我们看看如何使用吧!
## 如何使用
这里需要同时配置 `tailwindcss` 和 `postcss` 的配置文件才能起作用,其中 `tailwindcss` 配置修改的方式大体类似, `uni-app` `vue2/3` `postcss`插件的注册方式,有些许不同:
### tailwind.config.js 注册
首先在你的 `tailwind.config.js` 注册插件 `cssMacro`:
#### Tailwind CSS 3.x 配置
```js
const cssMacro = require('weapp-tailwindcss/css-macro');
/** @type {import('tailwindcss').Config} */
module.exports = {
// ...
plugins: [
/* 这里可以传入配置项,默认只包括 ifdef 和 ifndef */
cssMacro(),
],
};
```
#### Tailwind CSS 4.x 配置
> v4 推荐直接在入口 CSS 中通过 `@plugin` 引入。
```css
/* tailwind.css */
@import "tailwindcss";
@plugin "weapp-tailwindcss/css-macro";
/* 可选:为常用平台创建语义别名 */
@utility platform-weixin:(value) {
@apply ifdef-[MP-WEIXIN]:$(value);
}
@utility not-alipay:(value) {
@apply ifndef-[MP-ALIPAY]:$(value);
}
```
若需要自定义更多静态变体,可额外保留一个 `tailwind.config.ts` 以传入参数:
```ts
export default {
plugins: {
cssMacro: cssMacro({
variantsMap: {
wx: 'MP-WEIXIN',
'-wx': { value: 'MP-WEIXIN', negative: true },
},
}),
},
}
```
> [!TIP]
> `cssMacro` 的动态变体(`ifdef:` / `ifndef:`)依赖 Tailwind 内置的 `matchVariant`,请确保 Tailwind 版本 ≥ 3.2;在 v4 中该 API 同样可用。
### postcss 插件注册
对应的 `postcss` 插件位置为 `weapp-tailwindcss/css-macro/postcss`
值得注意的是,你必须把这个插件,注册在 `tailwindcss` 之后和 `@dcloudio/vue-cli-plugin-uni/packages/postcss` 之前。
> `@dcloudio/vue-cli-plugin-uni/packages/postcss` 为 vue2 cli项目特有,vue3不用管。
注册在 `tailwindcss` 之后很好理解,我们在针对 `tailwindcss` 的产物做修改,自然要在它执行之后处理,注册在 `@dcloudio/vue-cli-plugin-uni/packages/postcss` 之前则是因为 `uni-app` 样式的条件编译,靠的就是它。假如在它之后去处理不久已经太晚了嘛。
> 这里提一下 postcss 插件的执行顺序,假如注册是数组,那就是按照顺序执行,如果是对象,那就是从上往下执行,详见[官方文档](https://www.npmjs.com/package/postcss-load-config#ordering)
#### uni-app vite vue3
```diff
// vite.config.ts 文件
// postcss 插件配置
const postcssPlugins = [require('autoprefixer')(), require('tailwindcss')()];
// ... 其他省略
+ postcssPlugins.push(require('weapp-tailwindcss/css-macro/postcss'));
// https://vitejs.dev/config/
export default defineConfig({
plugins: vitePlugins,
css: {
postcss: {
plugins: postcssPlugins,
},
},
});
```
> 可以参考这个项目的配置 [demo/uni-app-vue3-vite](https://github.com/sonofmagic/weapp-tailwindcss/tree/main/demo/uni-app-vue3-vite)
#### uni-app vue2
vue2 cli 项目默认会带一个 `postcss.config.js` 我们之间直接在里面注册即可:
```diff
const webpack = require('webpack')
const config = {
parser: require('postcss-comment'),
plugins: [
// ...
require('tailwindcss')({ config: './tailwind.config.js' }),
// ...
+ require('weapp-tailwindcss/css-macro/postcss'),
require('autoprefixer')({
remove: process.env.UNI_PLATFORM !== 'h5'
}),
+ // 注意在 tailwindcss 之后和 这个之前
require('@dcloudio/vue-cli-plugin-uni/packages/postcss')
]
}
if (webpack.version[0] > 4) {
delete config.parser
}
module.exports = config
```
> 可以参考这个项目的配置 [demo/uni-app](https://github.com/sonofmagic/weapp-tailwindcss/tree/main/demo/uni-app)
### 配置完成
现在配置好了这2个地方,目前你就可以直接使用 `ifdef` 和 `ifndef` 的条件编译写法了!
```html
Web和微信小程序平台蓝色背景
非MP-WEIXIN平台红色背景
微信小程序为蓝色,不是微信小程序为红色
微信小程序为蓝色,不是微信小程序为红色
头条小程序蓝色
```
不过你肯定会觉得这种默认写法很烦!要写很多,不要紧,我还为你提供了自定义的方式,接下来来看看配置项吧!
## 配置项
这里提供了一份示例,
> uni-app `%PLATFORM%` 的所有取值可以参考这个[链接](https://uniapp.dcloud.net.cn/tutorial/platform.html#preprocessor)
```js
const cssMacro = require('weapp-tailwindcss/css-macro');
/** @type {import('tailwindcss').Config} */
module.exports = {
// ...
plugins: [
/* 这里可以传入配置项,默认只包括 ifdef 和 ifndef */
cssMacro({
// 是否包含 ifdef 和 ifndef,默认为 true
// dynamic: true,
// 传入一个 variantsMap
variantsMap: {
// wx 对应的 %PLATFORM% 为 'MP-WEIXIN'
// 有了这个配置,你就可以使用 wx:bg-red-300
wx: 'MP-WEIXIN',
// -wx,语义上为非微信
// 那就传入一个 obj 把 negative 设置为 true
// 就会编译出 ifndef 的指令
// 有了这个配置,你就可以使用 -wx:bg-red-300
'-wx': {
value: 'MP-WEIXIN',
negative: true
},
mv: {
// 可以使用表达式
value: 'H5 || MP-WEIXIN'
},
'-mv': {
// 可以使用表达式
value: 'H5 || MP-WEIXIN',
negative: true
}
}
}),
],
};
```
## IDE智能提示
只要你使用 `vscode`/`webstorm` 这类IDE,加上安装了 `tailwindcss` 的官方插件。
智能提示会根据你对 `cssMacro` 这个插件的配置,直接生成出来!
> 假如没有下方的智能提示出现,有可能是 `tailwindcss` 插件挂了,这时候可以改好配置之后 **重启** `vscode` 以重新运行插件
这里我们以上面 `配置项` 为例:
### 动态提示: ifdef-[] 和 ifndef-[]

### 配置的静态提示: wx 和 -wx

---
## Tailwindcss 2.x
目前,有些用户由于现有的项目,已经是 `webpack 4`, `postcss 7.x` 且无法往上升级,但是又想要使用 `tailwindcss`,
所以写了这个文档作为参考,在现有版本的情况下,**不推荐**任何的新项目使用
## 安装
在这种条件下,只能使用 `tailwindcss 2.x` 版本。
参考 https://v2.tailwindcss.com/docs/installation#post-css-7-compatibility-build 中的安装方式
安装好之后,一定要打开 `jit` 模式, https://github.com/icebreaker-trash/uni-app-vue2-tailwind-hbuilder-template/blob/master/tailwind.config.js
具体更多的细节,详见下方模板代码。
## vue2 hbuilderx 参考模板
注意,一定要在开发环境中设置
```js
process.env.TAILWIND_MODE = "watch"
```
才能正常热更新
模板源代码地址:
https://github.com/icebreaker-template/uni-app-vue2-tailwind-hbuilder-template
---
## 初始化 package.json
## 1. 安装
```bash npm2yarn
# 初始化 package.json
npm init
# 安装包
npm install -D tailwindcss @tailwindcss/postcss weapp-tailwindcss
```
## 2. 添加 `vite.config.ts`
```ts title="vite.config.ts"
export default defineConfig({
plugins: [
uni(),
UnifiedViteWeappTailwindcssPlugin({
rem2rpx: true,
tailwindcssBasedir: __dirname,
cssEntries: [
// 你 @import "weapp-tailwindcss"; 那个文件绝对路径
path.resolve(__dirname, './src/app.css'),
],
}),
],
css: {
postcss: {
plugins: [
tailwindcss({
base: __dirname
})
]
}
}
});
```
> tailwindcss@4 必须配置 `cssEntries` 并且使用绝对路径,否则 `tailwindcss` 生成的类名不会参与转译。
## 3. 添加样式
现在,在你的页面里面去随意的编写样式,比如 `bg-[#123456] text-[#654321]`, 然后运行到微信开发者工具即可
## 参考模板
- [uni-app-x-hbuilderx 模板](https://github.com/icebreaker-template/uni-app-x-hbuilderx)
- [uni-app-hbuilderx 模板](https://github.com/icebreaker-template/uni-app-hbuilderx-tailwindcss-v4)
---
## UniappCliStyle
在 `src/app.css` 中引入 `weapp-tailwindcss`,这个文件会作为 `cssEntries` 的入口:
```css title="src/app.css"
@import "weapp-tailwindcss";
```
为了解决 IDE 智能提示问题,再额外创建一个 `main.css` 并引入 `weapp-tailwindcss/css`。
```css title="src/main.css"
@import "weapp-tailwindcss/css";
@source not "dist";
```
在项目目录下的 `App.vue` 中,添加以下内容:
```html title="App.vue"
```
:::warning
千万不要在 `uni.scss` 中去引入 `tailwindcss`, `uni.scss` 本质上走的是 `scss.additionalData`, 它会在每一个 `scss` 文件的开头,都去添加 `uni.scss` 里的文件内容
所以这相当于你每个 `scss`/ `vue` 文件里面,都加了 `tailwindcss` 引入,那 `css` 体积就爆炸了
:::
---
## UniappHbuilderStyle
在 `src/app.css` 中引入 `weapp-tailwindcss`,这个文件会作为 `cssEntries` 的入口:
```css title="src/app.css"
@import "weapp-tailwindcss";
```
为了 IDE 智能提示,再额外创建一个 `main.css` 并引入 `weapp-tailwindcss/css`。
```css title="src/main.css"
@import "weapp-tailwindcss/css";
@source not "unpackage";
```
在项目目录下的 `App.vue` / `App.uvue`(uni-app x 项目) 然后添加以下内容:
```html title="App.vue"
```
> 添加 `@source not "unpackage";` 是为了避免 `HBuilderX` 差量编译死循环问题
:::warning
千万不要在 `uni.scss` 中去引入 `tailwindcss`, `uni.scss` 本质上走的是 `scss.additionalData`, 它会在每一个 `scss` 文件的开头,都去添加 `uni.scss` 里的文件内容
所以这相当于你每个 `scss`/ `vue` 文件里面,都加了 `tailwindcss` 引入,那 `css` 体积就爆炸了
:::
---
## Mpx
## 安装
```bash npm2yarn
npm install -D tailwindcss @tailwindcss/postcss postcss weapp-tailwindcss
```
## 配置
更改 `mpx.config.js` 注册 `weapp-tailwindcss`
```js title="mpx.config.js"
const { defineConfig } = require('@vue/cli-service')
const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
const path = require('node:path')
const tailwindPostcss = require('@tailwindcss/postcss')
module.exports = defineConfig({
outputDir: `dist/${process.env.MPX_CURRENT_TARGET_MODE}`,
pluginOptions: {
mpx: {
plugin: {
postcssInlineConfig: {
// tailwindcss@4 需要在此处注册 @tailwindcss/postcss,详见 templates/mpx-tailwindcss-v4/mpx.config.js
ignoreConfigFile: true,
plugins: [tailwindPostcss()]
},
srcMode: 'wx',
hackResolveBuildDependencies: ({ files, resolveDependencies }) => {
const path = require('path')
const packageJSONPath = path.resolve('package.json')
if (files.has(packageJSONPath)) files.delete(packageJSONPath)
if (resolveDependencies.files.has(packageJSONPath)) {
resolveDependencies.files.delete(packageJSONPath)
}
}
},
loader: {}
}
},
configureWebpack(config) {
// 添加的代码在这里
// highlight-start
config.plugins.push(
new UnifiedWebpackPluginV5({
appType: 'mpx',
rem2rpx: true,
cssEntries: [
// 你 @import "weapp-tailwindcss"; 那个文件绝对路径
path.resolve(__dirname, './src/app.css'),
],
})
)
// highlight-end
}
})
```
> tailwindcss@4 必须配置 `cssEntries` 并且使用绝对路径,否则 `tailwindcss` 生成的类名不会参与转译。
> tailwindcss@4 下必须在 `mpx.config.js` 里用 `postcssInlineConfig` 注册 `@tailwindcss/postcss`(同仓库 `templates/mpx-tailwindcss-v4/mpx.config.js` 的写法),否则插件不会生效,无需再单独维护 `postcss.config.js`。
## 添加样式
在 `src/app.css` 中引入 `weapp-tailwindcss`:
```css title="src/app.css"
@import "weapp-tailwindcss";
```
> 💡 如果你希望在任意样式文件中直接引用包内样式,请使用 `@import "weapp-tailwindcss/index.css";`。这样可以确保 `postcss-import` 解析到的是真实的 CSS 资源,避免出现 “Unknown word "use strict"” 这一类由于误解析到 JS 文件导致的构建报错。
### Tailwind CSS 样式引用指引
- **Tailwind CSS v3.x**:沿用旧模块名即可(例如 `@import 'tailwindcss/base.css'`、`@import 'tailwindcss/components.css'`、`@import 'tailwindcss/utilities.css'`)。
- **Tailwind CSS v4.x**:推荐直接引入 `weapp-tailwindcss` 提供的聚合样式:
```html title="src/app.mpx"
```
这样可以一次性获得 base / components / utilities,并规避 `postcss-import` 误解析 JS 入口的报错。如果你是从 v3 升级,只需将原来的三个 `@import` 换成这条语句即可。
然后在项目目录下,小程序全局的 `app.mpx` 中,通过 `@import` 引入该文件:
```html title="app.mpx"
```
更改好配置之后,直接启动即可
## 参考模版
https://github.com/icebreaker-template/mpx-tailwindcss-v4
---
## Patch
然后把下列脚本,添加进你的 `package.json` 的 `scripts` 字段里:
```json title="package.json"
"scripts": {
// highlight-next-line
"postinstall": "weapp-tw patch"
}
```
:::caution 使用 pnpm@10+
`pnpm@10` 默认只允许 `onlyBuiltDependencies` 中的包运行生命周期脚本。安装完本插件后,请执行 `pnpm approve-builds weapp-tailwindcss` 将其加入白名单,避免 `postinstall` 的 `weapp-tw patch` 被跳过。
:::
这是为了给 `tailwindcss@4` 打上支持 `rpx` 单位的补丁,否则它会把 `rpx` 认为是一种颜色
如需在补丁前强制刷新 `tailwindcss-patch` 的缓存,可改为:
```json title="package.json"
"scripts": {
"postinstall": "weapp-tw patch --clear-cache"
}
```
默认不清理缓存;只有当你怀疑缓存导致补丁未生效或目标不一致时,才需要添加 `--clear-cache`。***
---
## 开发参考手册
:::warning
由于 `tailwindcss@4.x` 本身还在快速的开发迭代中,即使是小版本也可能带有一些意外的 `Breaking Change`
所以以下内容可能会经常变更,如果发现已经过时,请提 `issue` 或者直接修复提 `pr`
:::
所以假如你要兼容更多的手机机型,请使用 `tailwindcss@3.x`。
## 定位的变化: 样式预处理器
相对于 `tailwindcss@3` 版本, `tailwindcss@4` 存在定位的重大变更
它直接变成了一个样式预处理器,和原生 `css` 已经它的规范相结合,相辅相成。
所以你在 `4.x` 版本中,不应该让 `tailwindcss` 和 `sass`,`less`,`stylus` 一起使用
详见: https://tailwindcss.com/docs/compatibility#sass-less-and-stylus
## 集成选择
`tailwindcss` 集成上提供了多种选择 (`cli`,`vite`,`postcss`),这里我们主要选择 `@tailwindcss/postcss`,原因如下:
1. `@tailwindcss/postcss` 兼容性更好,开发打包器使用 `vite` 和 `webpack` 的都能用,而 `@tailwindcss/vite` 这里只有 `vite` 能用。
2. `@tailwindcss/vite` 很容易和其他的 `vite` 插件起冲突,尤其是和 `uni-app` / `taro` 一起使用的时候,依赖注册的顺序和编译 `hook` 注册的顺序
3. `uni-app`/`taro` 这种框架,默认都是 `cjs` 加载的,而 `@tailwindcss/vite` 只提供了 `esm` 的版本,所以集成上可能会遇到问题
4. `tailwindcss@3.x` 是 `postcss` 插件,`@tailwindcss/postcss` 也是 `postcss` 插件,所以选择它,项目迁移升级的成本会更低。
所以,综合考虑下来,我们主要选择 `@tailwindcss/postcss`。
当然,你也完全可以使用 `uni-app vite vue3` + `@tailwindcss/vite` 这种组合。从编译速度出发, `@tailwindcss/vite` 会更快,但是可能需要一些额外的配置,行为也有可能和 `tailwindcss@3.x` 不一致。
## 小程序样式引入 `tailwindcss` 不同点
在小程序的样式文件中,引入 `tailwindcss` 的时候,需要把官方文档上写的 `@import "tailwindcss"` 替换为 `@import "weapp-tailwindcss"`。
```diff
- @import "tailwindcss";
+ @import "weapp-tailwindcss";
```
### 有什么区别?
`@import "weapp-tailwindcss"` 相比 `@import "tailwindcss"` 的主要区别是:
1. `"weapp-tailwindcss"` 没有 `"tailwindcss"` 中 `h5` `preflight` 的类(这些都是给 `h5` 用的,小程序用不到)
2. `"weapp-tailwindcss"` 中,不使用 `tailwindcss` 默认的 `@layer` 来控制样式优先级。这是因为小程序本身不支持 `css` `@layer` 这个特性,强行启用会造成一些样式难以覆盖的问题。
### 多端开发
假如你需要进行多端的开发,那么可以使用对应框架的样式条件编译写法,比如 `uni-app`:
```css
/* #ifdef H5 */
@import "tailwindcss";
/* #endif */
/* #ifndef H5 */
@import "weapp-tailwindcss";
/* #endif */
```
详见 https://uniapp.dcloud.net.cn/tutorial/platform.html
## css 作为配置文件
由于在 `tailwindcss@4` 中,配置文件默认为一个 `css` 文件,所以你需要显式的告诉 `weapp-tailwindcss` 你的入口 `css` 文件的绝对路径。
来让 `weapp-tailwindcss` 和 `tailwindcss` 保持一致的处理模式
> `cssEntries` 为一个数组,就是你 @import "weapp-tailwindcss"; 那些文件,可以有多个
```ts
{
cssEntries: [
// 就是你 @import "weapp-tailwindcss"; 那个文件
// 比如 tarojs
path.resolve(__dirname, '../src/app.css')
// 比如 uni-app (没有 app.css 需要先创建,然后让 `main` 入口文件引入)
// path.resolve(__dirname, './src/app.css')
],
}
```
假如不添加这个,会造成 `tailwindcss` 插件生成的样式,转义不了的问题。
> 插件会自动根据已安装的 Tailwind 版本开启 v4 模式。只有在调试自定义 `tailwindcss` 目录或多版本共存时,才需要在 `tailwindcss` 配置里手动指定 `version`。
## 使用 @apply
如果你想在 页面或者组件独立的 `CSS` 模块中使用 `@apply` 或 `@variant`,你需要使用 `@reference` 指令,来导入主题变量、自定义工具和自定义变体,以使这些值在该上下文中可用。
```css
/* 到你引入 weapp-tailwindcss 的 css 相对路径 */
@reference "../../app.css";
/* 如果你只使用默认主题,没有自定义,你可以直接 reference weapp-tailwindcss */
@reference "weapp-tailwindcss";
```
详见: https://tailwindcss.com/docs/functions-and-directives#reference-directive
## @layer 在小程序的降级方案
`tailwindcss@4` 使用原生的 `@layer` 去控制样式的优先级
> 如果你不知道什么是 `@layer`,你可以阅读这篇文档 https://developer.mozilla.org/zh-CN/docs/Web/CSS/@layer
但是像 `uni-app` / `taro` 这种框架,默认都是直接引入很多内置样式的。
于是就会出现下方尴尬的情况: 优先级 `(0,1,0)` 的 `class` 选择器样式无法覆盖 `(0,0,1)` 的标签选择器样式:

这种情况,你就非常需要兼容性降级方案,即使用 [`postcss-preset-env`](https://www.npmjs.com/package/postcss-preset-env) (`weapp-tailwindcss` 已经内置了这个插件了,你可以直接使用它的配置,详见 [cssPresetEnv](/docs/api/interfaces/UserDefinedOptions#csspresetenv))
这在开发需要兼容低版本移动端 h5 的时候很重要。
## 使用 pnpm
默认使用 `pnpm` 的时候,由于 `pnpm` 是无法使用幽灵依赖的
但是 `uni-app`/`taro` 出于一些历史原因,是需要幽灵依赖的,这时候可以在项目下创建 `.npmrc` 添加内容如下
```txt title=".npmrc"
shamefully-hoist=true
```
然后重新执行 `pnpm i` 安装包即可运行
## 智能提示
目前 `tailwindcss@4` 的 `vscode` 插件,会扫描目录下的 `css` 来获取 `tailwindcss` 的配置。
但是这里有个非常坑的点是,它不会去自动的扫描 `.vue` 文件里面的 `tailwindcss` 引入
这就导致,我们假如想在 `vue` 项目(比如 `uni-app`) 中获得智能提示,必须再随便创建一个 `main.css`,然后通过 `App.vue` 文件引入它
```css title="main.css"
@import "weapp-tailwindcss/css";
@source not "dist";
```
```html title="App.vue"
```
## 如何去除 preflight 样式
在引入 `@import "weapp-tailwindcss"` 时,默认会引入 `preflight` 样式。
### 什么是 preflight 样式
一些全局的 `reset` 样式,用来让一些标签行为统一的,比如你在你的样式中,看到的:
```css
view,text,::before,::after,::backdrop {
box-sizing: border-box;
margin: 0;
padding: 0;
border: 0 solid;
}
```
类似这样的就是 `weapp-tailwindcss` 给你的应用注入的 `preflight` 样式
### 解决方案
`@import "weapp-tailwindcss"` 本质上由三个部分组成:
```css
@import 'weapp-tailwindcss/theme.css';
@import 'weapp-tailwindcss/preflight.css';
@import 'weapp-tailwindcss/utilities.css';
```
所以想要去除 `preflight` 样式,只需像下面一样写即可
```diff
- @import "weapp-tailwindcss";
+ @import 'weapp-tailwindcss/theme.css';
+ @import 'weapp-tailwindcss/utilities.css';
```
## 使用大写单位 (h-[100PX]) 无效问题
默认情况下,在 `process.env.NODE_ENV === 'production'` 的时候, `tailwindcss` 会自动进入优化模式
它会进行 `CSS` 单位的校准,比如把大写的 `PX` 转化为小写的 `px`,你要禁用这个行为可以这样传入。
```js
export default {
plugins: {
"@tailwindcss/postcss": {
optimize: false
},
}
}
```
详见: [@tailwindcss/postcss](https://github.com/tailwindlabs/tailwindcss/blob/7779d3d080cae568c097e87b50e4a730f4f9592b/packages/%40tailwindcss-postcss/src/index.ts#L73C35-L73C72)
---
## Taro vite
## 安装
```bash npm2yarn
npm install -D tailwindcss @tailwindcss/postcss postcss weapp-tailwindcss
```
> 这里不使用 `@tailwindcss/vite` 是由于 `taro` 配置没法加载纯 `esm` 不是 `cjs` 的包, 会爆错误 `No "exports" main defined`
## 配置
```js title="config/index.ts"
{
compiler: {
type: 'vite',
vitePlugins: [
{
name: 'postcss-config-loader-plugin',
config(config) {
// 加载 tailwindcss
if (typeof config.css?.postcss === 'object') {
config.css?.postcss.plugins?.unshift(tailwindcss())
}
},
},
UnifiedViteWeappTailwindcssPlugin({
rem2rpx: true,
cssEntries: [
// 你 @import "weapp-tailwindcss"; 那个文件绝对路径
path.resolve(__dirname, '../src/app.css'),
],
}),
]
},
}
```
> tailwindcss@4 必须配置 `cssEntries` 并且使用绝对路径,否则 `tailwindcss` 生成的类名不会参与转译。
> 这里使用 `vite` 插件直接去加载 `tailwindcss`,这是由于 `taro4 vite` 不会自动去加载项目下的 `postcss.config.js`,所以只能定义这个 `postcss-config-loader-plugin`
## 添加样式
在项目目录下的 `src/app.css` 中,添加以下内容:
```css title="src/app.css"
@import "weapp-tailwindcss";
```
更改好配置之后,直接运行启动项目,微信开发者工具导入这个项目,即可看到效果。
## 参考模板
https://github.com/icebreaker-template/taro-vite-tailwindcss-v4
---
## Taro webpack
## 安装
```bash npm2yarn
npm install -D tailwindcss @tailwindcss/postcss postcss weapp-tailwindcss
```
## 配置
### 在你的根目录创建 `postcss.config.mjs`
```js title="postcss.config.mjs"
export default {
plugins: {
"@tailwindcss/postcss": {},
}
}
```
### 在你的 `app.css` 里面添加
```css
@import "weapp-tailwindcss";
```
### 注册插件
在项目的配置文件 `config/index` 中注册:
```js title="config/index.[jt]s"
// 假如你使用 js 配置,则使用下方 require 的写法
// const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
// const path = require('node:path')
{
// 找到 mini 这个配置
mini: {
// postcss: { /*...*/ },
// 中的 webpackChain, 通常紧挨着 postcss
webpackChain(chain, webpack) {
// 复制这块区域到你的配置代码中 region start
// highlight-start
chain.merge({
plugin: {
install: {
plugin: UnifiedWebpackPluginV5,
args: [{
// 这里可以传参数
rem2rpx: true,
cssEntries: [
// 你 @import "weapp-tailwindcss"; 那个文件绝对路径
path.resolve(__dirname, '../src/app.css'),
],
}],
},
},
})
// highlight-end
// region end
}
}
}
```
> tailwindcss@4 必须配置 `cssEntries` 并且使用绝对路径,否则 `tailwindcss` 生成的类名不会参与转译。
## 运行
然后执行命令发布到微信小程序
```bash npm2yarn
npm run dev:weapp
```
微信开发者工具导入这个项目,即可看到效果
## 参考模板
https://github.com/icebreaker-template/taro-webpack-tailwindcss-v4
---
## 高阶篇:性能、兼容与团队协作
Tailwind CSS 4 带来了更强大的原生语法,但在小程序环境中仍需平衡兼容性与团队协作。本篇从工程化视角出发,帮助你在真实项目中稳定地落地、优化与维护。
## 1. 处理 `@layer` 与兼容性
小程序运行时目前对 CSS Cascade Layers 支持有限,当你引用第三方组件或自定义样式时可能出现覆盖关系错乱。`weapp-tailwindcss` 内置的 `postcss-preset-env` 可将 `@layer` 转译成传统写法来提升兼容性。
```ts title="vite.config.ts"
export default defineConfig({
plugins: [
UnifiedViteWeappTailwindcssPlugin({
cssEntries: [
/* ... */
],
cssPresetEnv: {
stage: 1,
features: {
'cascade-layers': true,
},
},
}),
],
})
```
> 如果你只在微信小程序调试,可使用开发者工具的「自定义编译」观察处理前后的差异;若仍存在覆盖问题,可结合传统的 `!important` 或布局拆分策略。
额外提示:
- `cssSelectorReplacement.root` 默认包含 `['page', '.tw-root']`。当页面外的容器(例如自定义 tab bar、弹出层根节点等)需要承载 Tailwind 注入的 `--tw-*` 变量时,只需在容器上加上 `class="tw-root"` 即可复用整套预设,无需额外配置。下面是一个在自定义 tab bar 中注入主题变量的示例:
```xml title="custom-tab-bar/index.mpx"
```
搭配 `cssPreflight` 注入的变量或自定义 `@theme`,可以把 tab bar 的主题色、渐变背景等统一交给 Tailwind 管理。若你需要覆盖其他容器名称,仍可以通过配置把 `cssSelectorReplacement.root` 扩展为更多选择器。
- `cssPresetEnv` 会参与最终构建,请在发布前执行一次 `pnpm build:apps` 或对应的 `pnpm build` 命令确认产物
## 2. 多端共存与按需构建
团队常同时维护小程序与 H5 版本,此时可以通过多个 `@source` 区分模板范围,并结合条件编译实现按需打包:
```css title="src/app.css"
@source "../src/**/*.{vue,wxml}";
@source not "../src/**/*.h5.*"; /* 排除只用于 H5 的模板 */
/* H5 用 Tailwind 官方包,小程序继续用 weapp-tailwindcss */
/* #ifdef H5 */
@import "tailwindcss";
/* #endif */
/* #ifndef H5 */
@import "weapp-tailwindcss";
/* #endif */
```
当需要拆分体积时,可以把不同业务域的样式写到各自的 `entry.css`,再将路径加入 `cssEntries`:
```ts
UnifiedViteWeappTailwindcssPlugin({
cssEntries: [
path.resolve(import.meta.dirname, './src/app.css'),
path.resolve(import.meta.dirname, './src/features/order/app.css'),
],
})
```
这样 Tailwind 只会为实际引用的模板生成原子类,避免冗余。
## 3. 产物体积与性能优化
- **控制扫描范围**:`@source` 支持 `not` 语法,排除 `dist`、`node_modules` 等目录能显著加快增量编译
- **合理使用自定义工具类**:把相同组合提炼成 `@utility`,既减少模板体积,也方便统一调整
- **按需开启 `rem2rpx` / `px2rpx`**:在仅小程序端需要 rpx 的情况下,可以在多端构建中动态开启
- **缓存管理**:Tailwind 会在 `.tailwind` 写入缓存。CI 环境可缓存该目录以提升构建速度,发布前若需彻底清理运行 `pnpm exec tailwindcss --config tailwind.config.js --clean` 或直接删除缓存目录
## 4. 调试与质量保障
- **可视化定位**:使用 `outline` 类临时标记组件边界,例如在调试时加上 `outline outline-1 outline-dashed outline-brand/60`
- **断言样式存在**:核心组件可引入快照测试或 DOM 断言,结合 Vitest + @testing-library 验证关键类名
- **lint 约束**:在 `eslint-plugin-tailwindcss` 或团队约定的 lint 规则中,限制自定义类名必须通过 `@utility`
- **回归验证**:Tailwind 升级时执行 `pnpm test`, `pnpm e2e` 确认核心链路稳定,同时在主流机型(尤其是低版本安卓)上真机预览
## 5. 升级与维护策略
1. **版本对齐**:Tailwind 4 迭代频繁,升级前先在 `CHANGELOG` 与 GitHub Release 查 Breaking Change,再在测试分支试跑。
2. **切分 Changeset**:对外发布库时遵循 [Changesets](https://github.com/changesets/changesets) 约定,确保依赖者知道何时需要手动介入。
3. **文档同步**:团队内部记录 `@utility`、`@theme` 的设计规范,推荐把核心样式写进 Storybook 或内部组件示例库。
4. **遇到问题及时回馈**:`weapp-tailwindcss` 社区对 Tailwind 4 的需求反馈快速,遇到兼容问题可通过 Issue 或 PR 参与共建。
至此,你已经掌握了 Tailwind CSS 4 在小程序中的完整落地思路:从环境搭建、组件实践到性能与协同。结合现有的框架集成文档,就能为新成员提供一套体系化的学习路径。
---
## 入门篇:快速认识 Tailwind CSS 4 与 weapp-tailwindcss
Tailwind CSS 4 重新定义了“原子化”样式的组织方式:配置文件换成了 `CSS`,主题变量与自定义工具也变成了原生语法。这一变化对小程序生态同样生效,`weapp-tailwindcss` 已经适配了新的编译流程。本篇入门指南帮助你在 30 分钟内从零搭好一套 `tailwindcss@4` + `weapp-tailwindcss` 的基础开发环境,并理解最核心的概念。
## 本篇能学到什么
- 搭建一套可运行的 Tailwind CSS 4 + 小程序项目骨架
- 分清核心配置(`cssEntries`、`@source`、`@reference` 等)各自负责的事情
- 理解 `@tailwindcss/postcss`、`@tailwindcss/vite` 与编译插件的差异
- 掌握验证样式是否生效的最小闭环,避免“写了没生效”的常见坑
如果你还未接触过 `weapp-tailwindcss`,建议先浏览 [新手快速上手(Tailwind CSS 3.x)](/docs/quick-start/install) 了解插件能解决的问题,再回来完成 4.x 的配置。
## 环境准备
| 名称 | 说明 |
| --- | --- |
| Node.js ≥ 18 | Tailwind CSS 4 要求更高的 Node 版本,建议使用 LTS 20 |
| pnpm ≥ 8 | Monorepo 与文档项目统一使用 `pnpm` |
| 小程序框架 | 任选 `weapp-vite`、`uni-app`、`taro` 等,推荐使用现成模板 |
| 代码编辑器 | VS Code 并安装 `Tailwind CSS IntelliSense` 插件 |
初始化项目后,执行一次 `pnpm install` 以及框架 CLI 的初始化命令(如 `pnpm create @tarojs/cli`)。随后即可进入 Tailwind CSS 配置步骤。
## 步骤一:安装依赖
在项目根目录执行:
```bash
pnpm add -D tailwindcss@latest @tailwindcss/postcss postcss weapp-tailwindcss
```
> `@tailwindcss/postcss` 兼容 Vite、Webpack、Rspack 等大多数构建链路;对于纯 Vite 项目也可以酌情改用 `@tailwindcss/vite`,但在小程序场景下 `postcss` 方案更稳定。
## 步骤二:注册 weapp-tailwindcss 插件
以 `weapp-vite` 为例(不同框架请对照对应的 [集成指南](/docs/quick-start/v4)):
```ts title="vite.config.ts"
export default defineConfig({
plugins: [
UnifiedViteWeappTailwindcssPlugin({
// 常用内置能力:开启 px 自动转换
rem2rpx: true,
cssEntries: [
// 声明 Tailwind 的入口 CSS,必须是绝对路径
path.resolve(import.meta.dirname, './src/app.css'),
],
}),
],
})
```
`cssEntries` 对 `tailwindcss@4` 至关重要,它告诉 `weapp-tailwindcss` 哪些 CSS 需要参与编译与转义。漏掉该配置将导致产物中缺失样式。
## 步骤三:配置 PostCSS
```js title="postcss.config.js"
export default {
plugins: {
'@tailwindcss/postcss': {},
},
}
```
Tailwind CSS 4 已内置 Autoprefixer,无需手动补充。若项目仍需其他 PostCSS 插件,保持旧的写法即可。
## 步骤四:创建入口 CSS
在 `src/app.css` 中写入:
```css title="src/app.css"
@import "weapp-tailwindcss";
/* 声明模板扫描路径,确保原子类能被收集 */
@source "../src/**/*.{vue,tsx,jsx,svelte,wxml}";
/* 需要自定义设计令牌时可在此编写 */
@theme {
--color-brand: oklch(67% 0.2 264);
--spacing-safe: clamp(12px, 1.2vw + 8px, 24px);
}
```
`@source` 是 Tailwind 4 的新写法,用于替代旧版本的 `content` 配置。路径请根据项目结构调整。若你需要在局部样式文件使用 `@apply`,在对应文件顶部添加 `@reference "./app.css";`。
## 步骤五:验证类名是否生效
创建一个最小页面(以 `src/pages/index/index.vue` 为例):
```html title="src/pages/index/index.vue"
Tailwind CSS 4
欢迎来到 weapp-tailwindcss
现在可以尝试修改 bg-brand 或自定义 utility。
```
> `py-safe` 是我们在上文 `@theme` 中声明的自定义变量(通过 `--spacing-safe` 导出),可验证主题自定义是否生效。
运行框架命令(如 `pnpm dev:weapp` 或 `pnpm run build -- --watch`),查看开发者工具中的页面是否渲染出预期样式。如果没有:
- 检查 `cssEntries` 是否指向了正确路径
- 确认 `@source` 是否包含当前文件扩展名
- 若在单文件组件内使用 `@apply`,确保添加了 `@reference`
## 常见下一步
- 阅读 [Tailwind CSS 4 官方文档](https://tailwindcss.com/docs/installation) 了解更多原生指令
- 针对不同框架的集成细节,请查阅「🧪Tailwind CSS @4.x」分类中的各篇文档
- 想理解 `@layer` 在小程序下的降级方案,可继续阅读本教程的 [进阶篇](/docs/quick-start/v4/tutorial/workflow) 与 [高阶篇](/docs/quick-start/v4/tutorial/advanced)
完成本篇后,你已经拥有了稳定的基础开发环境。接着让我们通过真实业务组件把 Tailwind CSS 4 的能力串联起来。
---
## 进阶篇:用 Tailwind CSS 4 构建真实页面
基础环境搭建完成后,真正的挑战来自“如何把抽象的原子类应用到真实业务”。本篇精选小程序常见的页面模块,结合 `tailwindcss@4` 的新指令,总结出一套从设计拆解到代码落地的流程。
## 工具优先的心智模型
Tailwind CSS 的核心不在于背公式,而是把 UI 拆成「布局」「排版」「状态」三个维度,然后使用类名组合快速拼装。Tailwind 4 进一步引入 `@theme`、`@utility` 等指令,让自定义能力与项目约束保持同步:
- `@theme` 管理设计令牌:颜色、间距、字号、阴影等
- `@utility` 声明可复用的工具类,代替传统的 `.btn { ... }`
- `@variant` / `@custom-variant` 管理状态类(如 `active:`、`dark:`)
掌握这些指令后,就可以在不离开 CSS 语法的前提下扩展 Tailwind。
## 1. 拆解一个卡片组件
以「订单卡片」为例,先在 `src/components/order-card/index.vue` 写出骨架:
```html title="src/components/order-card/index.vue"
{{ createdAt }}
{{ amount }}
```
接下来在 `src/components/order-card/index.css` 中使用 Tailwind 原子类重构:
```css title="src/components/order-card/index.css"
@reference "../../app.css";
/* 使用 @utility 提升可读性 */
@utility order-card {
@apply block rounded-3xl bg-white shadow-lg shadow-slate-200/70 p-5 space-y-4;
}
@utility order-card__header {
@apply flex items-center justify-between gap-3;
}
@utility order-card__title {
@apply text-base font-semibold text-slate-900;
}
@utility order-card__meta {
@apply flex items-center justify-between text-sm text-slate-500;
}
@utility order-card__status {
@apply inline-flex items-center gap-1 rounded-full px-3 py-1 text-xs font-medium uppercase tracking-[0.28em];
}
/* 通过 @variant 声明业务状态 */
@custom-variant status-pending (&[data-status="pending"]);
@custom-variant status-finished (&[data-status="finished"]);
@custom-variant status-failed (&[data-status="failed"]);
.order-card__status {
@apply status-pending:bg-amber-100 status-pending:text-amber-600;
@apply status-finished:bg-emerald-100 status-finished:text-emerald-600;
@apply status-failed:bg-rose-100 status-failed:text-rose-600;
}
```
关键点:
- 使用 `@reference` 让局部样式文件继承入口 CSS 中的主题与工具
- `@utility` 让类名语义化,同时还能继续 `@apply` 原子类
- `@custom-variant`(Tailwind 4 新增)能让业务状态转换成语义化前缀
最后在组件实例上应用:
```html title="src/pages/index/index.vue"
自动续费:
```
## 2. 构建可复用的设计令牌
Tailwind 4 把主题抽象为原生 CSS 变量。你可以在 `app.css` 中集中维护令牌,再通过 `@theme` 输出:
```css title="src/app.css" {2-7}
@import "weapp-tailwindcss";
@theme {
--color-brand: oklch(66% 0.21 268);
--color-brand-muted: oklch(80% 0.04 268);
--radius-xl: 24px;
--shadow-elevated: 0 18px 40px -20px rgb(99 102 241 / 45%);
}
```
然后在业务样式中直接引用这些变量,或结合 Tailwind 的 `bg-[...]` 写法:
```css
.order-card {
@apply shadow-[var(--shadow-elevated)];
}
.order-card__status {
@apply status-finished:bg-[var(--color-brand-muted)] status-finished:text-[var(--color-brand)];
}
```
得益于 CSS 变量特性,你还可以在不同页面覆写 `:root` 或对应容器的变量,以实现主题切换。
## 3. 管理复杂布局与响应式
小程序虽然没有传统意义上的宽度断点,但我们仍可以借助媒体查询、`min()` / `max()` 等函数实现容错布局:
```css
@layer utilities {
@responsive {
@media (min-width: 560px) {
.md\\:card-grid {
display: grid;
grid-template-columns: repeat(2, minmax(0, 1fr));
gap: clamp(16px, 4vw, 36px);
}
}
}
}
```
在页面中配合默认的原子类即可:
```html
```
对于需要横向滚动的卡片,Tailwind 4 提供的 `snap-x`, `snap-mandatory`, `snap-center` 等类仍旧适用,不同端的处理逻辑交给 `weapp-tailwindcss`。
## 4. 多文件协作与团队约定
当项目迎来多人协作时,建议遵循以下约定:
1. **入口 CSS 只做聚合**:集中维护 `@import`、`@source` 与 `@theme`,其余逻辑拆到独立文件。
2. **组件目录内固定 `index.css`**:组件内声明 `@utility`、`@apply`,并写在组件同名文件夹下,便于按需引用。
3. **公共工具抽成包**:例如 `src/styles/utilities/forms.css`,内部声明所有表单相关的 `@utility`。
4. **lint 与提示配置**:确保团队成员的 VS Code `tailwindCSS.experimental.classRegex` 包含 `.wxml`、`.vue` 等模板。
## 5. 调试与性能提示
- Tailwind 4 的编译沿用增量模式,`pnpm run:watch` 时生成的原子类会写入缓存。需要彻底清理时删除 `.tailwind`、`node_modules/.cache/tailwind`。
- 小程序开发者工具不支持 `@layer`,若遇到覆盖问题,可以开启 `cssPresetEnv` 的降级行为,详情见 [高阶篇](/docs/quick-start/v4/tutorial/advanced)。
- 借助 `pnpm dev:h5`(部分框架提供)可快速在浏览器预览,调试完后再回到真机验证。
完成本篇后,你应该可以把 Tailwind 应用到实际业务模块,并形成一套可复用的组件写法。接下来,我们会关注性能优化、跨端适配与团队协作等更高阶的话题。
---
## HBuilderX
---
## uni-app cli vue3 vite(V4)
## 1. 安装
```bash npm2yarn
npm install -D tailwindcss @tailwindcss/postcss weapp-tailwindcss
```
## 2. 配置 `vite.config.ts`
```ts title="vite.config.ts"
export default defineConfig({
plugins: [
uni(),
UnifiedViteWeappTailwindcssPlugin({
rem2rpx: true,
cssEntries: [
// 你 @import "weapp-tailwindcss"; 那个文件绝对路径
path.resolve(import.meta.dirname, './src/app.css'),
],
}),
],
css: {
postcss: {
plugins: [
tailwindcss(),
],
},
},
});
```
> tailwindcss@4 必须配置 `cssEntries` 并且使用绝对路径,否则 `tailwindcss` 生成的类名不会参与转译。
## 3. 添加样式
接着直接运行 `npm run dev:mp-weixin`,
微信开发者工具导入这个项目,即可看到效果
{/* :::warning
这里必须创建一个额外的 `css` 文件,而不是直接在 `App.vue` 里的 `style` 标签下直接写,
这是因为 `@tailwindcss/vite` 目前只转化 `.css` 文件。后续可能会支持更多格式的文件,比如 `vue` 编译的中间文件
详见 http://github.com/tailwindlabs/tailwindcss/blob/main/packages/%40tailwindcss-vite/src/index.ts#L122 中的 `isCssFile` 判断
::: */}
## 参考模板
[uni-app-tailwindcss-v4](https://github.com/icebreaker-template/uni-app-tailwindcss-v4)
---
## uni-app cli vue2 webpack(V4)
## 安装
```bash npm2yarn
npm install -D tailwindcss @tailwindcss/postcss postcss weapp-tailwindcss
```
## 配置
### 创建 `vue.config.js`
```js title="vue.config.js"
const { UnifiedWebpackPluginV5 } = require('weapp-tailwindcss/webpack')
const path = require('node:path')
/**
* @type {import('@vue/cli-service').ProjectOptions}
*/
const config = {
// some option...
configureWebpack: (config) => {
config.plugins.push(
new UnifiedWebpackPluginV5({
rem2rpx: true,
cssEntries: [
// 你 @import "weapp-tailwindcss"; 那个文件绝对路径
path.resolve(__dirname, './src/app.css'),
],
})
)
}
// other option...
}
module.exports = config
```
> tailwindcss@4 必须配置 `cssEntries` 并且使用绝对路径,否则 `tailwindcss` 生成的类名不会参与转译。
## 配置 `postcss.config.js`
```js title="postcss.config.js"
const path = require('path')
const webpack = require('webpack')
const config = {
parser: require('postcss-comment'),
plugins: [
// highlight-next-line
require('@tailwindcss/postcss')(), // 只添加这一行
require('postcss-import')({
resolve (id, basedir, importOptions) {
if (id.startsWith('~@/')) {
return path.resolve(process.env.UNI_INPUT_DIR, id.substr(3))
} else if (id.startsWith('@/')) {
return path.resolve(process.env.UNI_INPUT_DIR, id.substr(2))
} else if (id.startsWith('/') && !id.startsWith('//')) {
return path.resolve(process.env.UNI_INPUT_DIR, id.substr(1))
}
return id
}
}),
require('autoprefixer')({
remove: process.env.UNI_PLATFORM !== 'h5'
}),
require('@dcloudio/vue-cli-plugin-uni/packages/postcss')
]
}
if (webpack.version[0] > 4) {
delete config.parser
}
module.exports = config
```
## 添加样式
然后直接运行到小程序,微信开发者工具导入这个项目,即可看到效果
## 参考模板
https://github.com/icebreaker-template/uni-app-webpack-tailwindcss-v4
---
## uni-app x
:::warning
tailwindcss@4 版本,暂时只支持 hbuilderx uni-app x 跨 `h5` 和 `小程序` 平台,
原生安卓和IOS平台无法支持,因为 uni-app x 目前对 css 各种现代语法的兼容较差,兼容不了 tailwindcss@4 生成的样式
未来此功能的适配,取决于 uni-app x 团队对现代 css 的兼容程度
(2025-07-27)
:::
---
## Weapp-vite
## 安装
```bash npm2yarn
npm install -D tailwindcss @tailwindcss/postcss postcss weapp-tailwindcss
```
## 配置
更改 `vite.config.ts` 注册 `weapp-tailwindcss`
```js title="vite.config.ts"
export default defineConfig({
plugins: [
UnifiedViteWeappTailwindcssPlugin({
rem2rpx: true,
cssEntries: [
// app.css 的路径
path.resolve(import.meta.dirname, './app.css'),
],
}),
],
})
```
添加 `postcss.config.js` 注册 `@tailwindcss/postcss`
```js title="postcss.config.js"
export default {
plugins: {
'@tailwindcss/postcss': {},
},
}
```
## 添加样式
在项目目录下,小程序全局的 `app.css` 中,添加以下内容:
```css title="app.css"
@import "weapp-tailwindcss";
```
更改好配置之后,直接启动即可
---
## wxs的转义与处理
:::info
`2.5.2+` 版本中,已经添加了对 `wxs`,`sjs`等视图层运行 `js` 的转义和处理,默认关闭
具体见配置项:
- [`wxsMatcher`](/docs/api/interfaces/UserDefinedOptions#wxsmatcher)
- [`inlineWxs`](/docs/api/interfaces/UserDefinedOptions#inlinewxs)
:::
---
## weapp-tw CLI 使用指南
`weapp-tailwindcss` 自带一个 `weapp-tw` 命令行工具,负责提前给 Tailwind CSS 打补丁、生成类名缓存以及收集 token。以下内容介绍常用命令及最佳实践。
## 常见场景
| 场景 | 命令 | 说明 |
| --- | --- | --- |
| 给 Tailwind CSS 打补丁、注入 `rpx` 支持 | `npx weapp-tw patch` | 运行一次即可,推荐写在 `postinstall`;支持 `--cwd` 指向子包目录。 |
| 强制刷新补丁缓存后再打补丁 | `npx weapp-tw patch --clear-cache` | 默认不会清理缓存;仅在怀疑缓存导致补丁未生效或版本不一致时使用。 |
| 在 monorepo 针对子包补丁 | `pnpm --filter exec weapp-tw patch --cwd .` | `pnpm` 场景建议显式传 `--cwd .`,每个子包只写入自己的缓存,避免 hoist 后的 `node_modules` 不一致。 |
| 一键扫描 workspace 并补丁 | `weapp-tw patch --workspace --cwd ` | 自动读取 `pnpm-lock.yaml`/`pnpm-workspace.yaml` 批量补丁,跳过未安装 Tailwind 的包,并输出每个子包状态。 |
| 收集 Tailwind 产出的类名缓存 | `npx weapp-tw extract --css src/app.css` | 适用于 Tailwind v3/v4,v4 需传入 `--css`,生成 `.tw-patch/tw-class-cache.*`,支持 `--output`/`--format`。 |
| 输出 Tailwind token 和定位信息 | `npx weapp-tw tokens --format grouped-json` | 调试 `content` 配置时非常有用,可与 `--no-write` 一起纯输出。 |
## `patch` 子命令
### 功能
- 扫描当前工作目录所依赖的 `tailwindcss`,给其打上 `rpx` 单位补丁。
- 暴露 Tailwind 运行时上下文,供 `webpack`/`vite`/`gulp` 插件复用。
- 检测到未安装 Tailwind 时会输出中文警告。
### 常用参数
| 参数 | 默认值 | 含义 |
| --- | --- | --- |
| `--cwd ` | `WEAPP_TW_PATCH_CWD` \| `INIT_CWD` \| `npm_config_local_prefix` \| 当前工作目录 | 指定要补丁的子包目录,等价于先 `cd`。默认会按顺序读取上述环境变量,避免在 `pnpm`/CI 里被 wrapper 覆盖成根目录。 |
| `--record-target` | `true` | 默认记录本次打补丁对应的 `tailwindcss` 根路径到子包专属的 `node_modules/.cache/weapp-tailwindcss//tailwindcss-target.json`,包含 `cwd`、Tailwind 路径、补丁版本与时间戳;如需关闭请传 `--record-target false`。 |
| `--clear-cache` | `false` | 按需清理 `tailwindcss-patch` 缓存目录后再执行补丁。默认不清理,避免不必要的 IO 和 CI 侧效应。 |
| `--workspace` | `false` | 批量扫描 workspace(`pnpm-lock.yaml`/`pnpm-workspace.yaml`/`workspaces`),逐个子包执行 patch 并输出“补丁/跳过/失败”状态。 |
默认会记录补丁目标,运行日志类似:
```bash
$ pnpm --filter demo/native-mina weapp-tw patch
weapp-tw patch 绑定 Tailwind CSS -> ./node_modules/tailwindcss (v3.4.18)
记录 weapp-tw patch 目标 -> ./node_modules/.cache/weapp-tailwindcss//tailwindcss-target.json
Tailwind CSS 运行时补丁已完成。
```
随后每次启动构建工具,运行时会输出 `tailwindcss-patcher 绑定 Tailwind CSS -> ...`;若检测到与缓存记录不一致,会自动重打补丁并刷新记录,无需手动清理跨包告警。若不希望生成记录,可在命令后追加 `--record-target false`。补丁记录按子包(package.json 路径 hash)隔离,避免 `pnpm` hoist 或 `workspace:` 互相引用时互相覆盖。
## `extract` 子命令
```bash
npx weapp-tw extract --css src/app.css --format lines
```
- `--css`:Tailwind 入口 CSS。v4 必填;v3 可省略以沿用 Tailwind 默认入口。
- `--output`:指定输出文件,默认写入 `.tw-patch/tw-class-cache.json`。
- `--format`:`json`/`lines`,配合 `--no-write` 可仅打印到终端。
- `--cwd` 与 `patch` 一致,也支持放在子包里执行。
生成的缓存可以让构建器快速读取 `tailwindcss` 编译结果,减少重复启动的开销。
## `tokens` 子命令
```bash
npx weapp-tw tokens --format grouped-json --group-key absolute
```
- `--format`:`json`、`lines` 或 `grouped-json`。后一种会按文件分组,便于排查 `content` 匹配不到的问题。
- `--group-key`:`relative`(默认)/`absolute`,决定输出路径的基准。
- `--no-write`:终端预览,不落盘;默认写入 `.tw-patch/tw-token-report.json`。
输出的数据包含扫描到的文件、类名 token、出现位置(行列)、以及被跳过的文件列表。
## 快速排查指引
1. **始终在子包目录执行 `weapp-tw patch`**:`pnpm --filter my-demo weapp-tw patch --cwd demo/my-demo`。
2. **如确实不需要追踪,可传 `--record-target false`**,避免生成额外 JSON。
3. **看到自动重补丁/记录迁移提示**:确认日志里的 Tailwind 路径与子包一致,`pnpm --filter ... exec weapp-tw patch --cwd .` 或 `weapp-tw patch --workspace --cwd ` 可避免 `INIT_CWD` 导致的跨包记录污染。
4. **类名缺失**: 用 `weapp-tw extract` 或 `weapp-tw tokens --no-write` 辅助定位是哪段代码没有被 Tailwind `content` 收录。
5. **需要强制指定根目录时**:在 monorepo 根执行 `WEAPP_TW_PATCH_CWD=$PWD weapp-tw patch --workspace`,可覆盖外层脚本设置的 `INIT_CWD`,确保一次性为所有子包补丁并写入各自的缓存记录。
配合这些命令,可以更直观地观察 Tailwind 依赖解析与补丁状态,减少“rpx 被当成颜色” 等由于上下游不一致导致的问题。
---
## uni-app x 专题
跨端原子化样式方案
Tailwind CSS × uni-app x
一键使用模板项目(推荐)
或者按步骤手动集成
## 这篇文档适合谁
- 想在 uni-app x 项目里使用 Tailwind CSS 的开发者
- 需要一套能同时覆盖 Web/小程序/Android/iOS/鸿蒙 的原子化样式方案
- 希望以最少的改动尽快起步,并有清晰的后续扩展路线
## 你将收获什么
- 完整的从 0 到 1 集成流程(含运行与验证)
- 可复用的模板项目与配置清单
- 多端开发的实践建议与避坑说明
:::info 支持范围
当前跨端集成仅支持 `tailwindcss@3.x`。
`tailwindcss@4.x` 生成的 CSS 依赖诸多现代特性,`uni-app x` 暂未全部覆盖,故不建议在该场景使用 v4。
:::
## 最快开始
- 想最快跑起来:点击上方「一键使用模板项目」,按 README 步骤打开 HBuilderX 运行即可
- 想了解每一步:前往「手动集成」教程 → 快速集成
## 开发建议(从用户出发)
- 推荐编辑器协作:用 VS Code 写代码,用 HBuilderX 负责运行与构建
- 首选 Android 端调试:CSS 兼容度一般是 Web > 小程序 > App(Android/iOS/鸿蒙)。先用 Android 模拟器打通路径,跨端成本最低
- 组件语义注意:原生 App 端文字需放在 `` 标签,且文本样式需要直接作用在该元素上
- 渐进增强:若某些样式在 App 端受限,优先保证 Android 端体验,再按需做条件编译适配小程序/Web
## 为什么推荐先用 Android
1) 原生端样式约束更严格,例如文本必须使用 ``,许多 CSS 特性仍在补齐中
2) 如果你的页面在 Android 端无告警、展示正确,迁移到小程序与 Web 的心智负担会小很多
3) iOS/鸿蒙的调试门槛更高(设备/系统要求),多数团队以 Android 作为优先目标更务实
## 常见问题
### VS Code 对 uvue/uts 的高亮与跳转
安装官方语言服务插件:
- ID: dcloud-ide.hbuilderx-language-services
- 说明: 支持 uni-app x 项目的提示、悬浮、转到定义、查找引用、校验等
- 链接: https://marketplace.visualstudio.com/items?itemName=dcloud-ide.hbuilderx-language-services
### Tailwind CSS 智能提示
VS Code 原生不识别 `uvue/uts`,建议为 Tailwind 扩展加上语言映射。在项目根目录创建 `.vscode/settings.json`:
```json title=".vscode/settings.json"
{
"tailwindCSS.includeLanguages": {
"uvue": "html",
"uts": "javascript"
}
}
```
### 运行方式
目前 `uni-app x` 尚无 CLI,需通过 HBuilderX 进行运行与构建。
建议配合 Android 模拟器进行开发调试。
## 接下来
- 跟着步骤手动完成集成:快速集成
- 直接基于模板起步:uni-app x + Tailwind 模板(HBuilderX)
---
## 快速集成
## 最简单:直接用模板项目(推荐)
立即上手而不纠结配置细节,点击下面链接即可:
使用模板一键开始
打开后按 README 步骤,用 HBuilderX 运行到 Android 模拟器或真机即可看到效果。
---
## 手动集成(由浅入深)
你也可以按下面步骤,从零开始完成配置。
### 前置条件
- 已安装最新 HBuilderX
- 安装 Node.js(建议 ≥ 18)
- 建议准备 Android 模拟器(或真机),便于快速验证
### 1) 创建项目
在 HBuilderX 中创建一个全新的 `uni-app x` 项目;随后在项目根目录初始化 `package.json`:
```bash npm2yarn
npm init -y
```
> 也可以手动创建 `package.json` 文件。
### 2) 安装并引入 Tailwind CSS 3
```bash npm2yarn
# 安装 tailwindcss@3 所需依赖
npm i -D tailwindcss@3 postcss autoprefixer
```
```bash npm2yarn
# 初始化 Tailwind 配置文件
npx tailwindcss init
```
在应用入口 `App.uvue` 中全局引入:
```html title="App.uvue"
```
### 3) 安装 weapp-tailwindcss 并添加补丁脚本
```bash npm2yarn
npm i -D weapp-tailwindcss
```
在 `package.json` 中增加 `postinstall` 脚本:
```json title="package.json"
{
"scripts": {
// highlight-next-line
"postinstall": "weapp-tw patch"
}
}
```
> 了解原因可阅读:weapp-tailwindcss 使用说明
### 4) 在 uni-app x 中注册 weapp-tailwindcss
先创建一个简单的路径工具函数,方便在配置里引用绝对路径:
```js title="shared.js"
const path = require('node:path')
function r(...args) {
return path.resolve(__dirname, ...args)
}
module.exports = { r }
```
创建 `vite.config.ts` 并注册插件(注意 `uniAppX` 预设来自 `weapp-tailwindcss/presets`):
```js title="vite.config.ts"
export default defineConfig({
plugins: [
uni(),
UnifiedViteWeappTailwindcssPlugin(
uniAppX({
base: __dirname,
rem2rpx: true,
}),
),
],
css: {
postcss: {
plugins: [
tailwindcss({
config: r('./tailwind.config.js'),
}),
],
},
},
})
```
### 5) 配置 Tailwind
使用绝对路径包含所有需要提取原子类的文件:
```js title="tailwind.config.js"
const { r } = require('./shared')
/** @type {import('tailwindcss').Config} */
module.exports = {
content: [
r('./pages/**/*.{uts,uvue}'),
r('./components/**/*.{uts,uvue}'),
],
corePlugins: {
// 由 uni-app x 提供基础样式,这里关闭 preflight 避免冲突
preflight: false,
},
}
```
如需从更多目录提取样式,按需扩展 `content` 的 glob。
### 6) 运行与验证
- 在 HBuilderX 中点击「运行」并选择目标平台(推荐 Android 模拟器/真机)
- 新建/打开任意页面,写入示例类名验证:
```html
Hello Tailwind on uni-app x
```
### 7) 编辑器智能提示(可选)
VS Code 配合插件体验最佳。为 Tailwind 扩展增加语言映射,让其识别 `uvue/uts`:
```json title=".vscode/settings.json"
{
"tailwindCSS.includeLanguages": {
"uvue": "html",
"uts": "javascript"
}
}
```
同时安装官方语言服务插件(ID: dcloud-ide.hbuilderx-language-services)以获得完整语法支持。
---
## 重要说明与限制
- 仅推荐在 `tailwindcss@3.x` 下跨端使用(v4 在该场景下暂不兼容)
- 原生 App 端对文本与部分 CSS 特性有约束:文本使用 `` 元素,且样式需直接作用其上
- 如遇到 HBuilderX 控制台 CSS 警告,请按提示做兼容性调整或采用条件编译